
Процедуры и функции для работы с OpenOffice
Владимир Ермаков, Королевство Дельфи
Все в мире развивается по спирали. Раньше программисты разрабатывали механизмы взаимодействия между Delphi и MSExcel, теперь они методом проб и ошибок создают приложения для создания документов в OpenOffice. Надеюсь, что эта статья сэкономит время и усилия для решения более важных проблем, чем открытие шаблона и поиск нужной ячейки.
Автор ни в коем случае не возлагает на себя лавры разработчика-первооткрывателя. Очень многое из данной статьи лежит в интернете на разных сайтах. Например — и др.
Другие процедуры и функции были созданы прямо в процессе работы над заданием. Все было проверено на работоспособность. Итак, начнем.
Для удобства работы, вынесем базовые функции и процедуры в новый класс
type TopofCalc = class(TObject)
при работе с таблицами, информация о типе документа может принимать следующие состояния:
type TTipooCalc = (ttcError, ttcNone, ttcExcel, ttcOpenOffice);
данные функции определяет тип приложения
function TopofCalc.GetIsExcel: boolean; begin result:= (Tipoo=ttcExcel); end;
function TopofCalc.GetIsOpenOffice: boolean; begin result:= (Tipoo=ttcOpenOffice); end;
и произведена ли его загрузка
function TopofCalc.GetProgLoaded: boolean; begin result:= not (VarIsEmpty(Programa) or VarIsNull(Programa)); end;
function TopofCalc.GetDocLoaded: boolean; begin result:= not (VarIsEmpty(Document) or VarIsNull(Document)); end;
запуск приложения…
procedure TopofCalc.LoadProg; begin if ProgLoaded then CloseProg; if ((UpperCase(ExtractFileExt(FileName))='.XLS') or (UpperCase(ExtractFileExt(FileName))='.XLT')) then begin //Excel... Programa:= CreateOleObject('Excel.Application'); Programa.Application.EnableEvents:=false; Programa.displayAlerts:=false; if ProgLoaded then Tipoo:= ttcExcel; end; // Another filetype? Let's go with OpenOffice... if ((UpperCase(ExtractFileExt(FileName))='.ODS') or (UpperCase(ExtractFileExt(FileName))='.OTS')) then begin //OpenOffice.calc... Programa:= CreateOleObject('com.sun.star.ServiceManager'); if ProgLoaded then Tipoo:= ttcOpenOffice; end; //Still no program loaded? if not ProgLoaded then begin Tipoo:= ttcError; raise Exception.create('TopofCalc.create failed, may be no Office is installed?'); end; end;
проведя все необходимые проверки, мы можем создать электронную таблицу
procedure TopofCalc.NewDoc; var ooParams: variant; begin if not ProgLoaded then raise exception.create('No program loaded for the new document.'); if DocLoaded then CloseDoc; DeskTop:= Unassigned; if IsExcel then begin Programa.WorkBooks.Add(); Programa.Visible:= Visible; Document:= Programa.ActiveWorkBook; ActiveSheet:= Document.ActiveSheet; end; if IsOpenOffice then begin Desktop:= Programa.CreateInstance('com.sun.star.frame.Desktop'); ooParams:= VarArrayCreate([0, 0], varVariant); ooParams[0]:= ooCreateValue('Hidden', not Visible); Document:= Desktop.LoadComponentFromURL('private:factory/scalc', '_blank', 0, ooParams); ActivateSheetByIndex(1); end; end;
а теперь закрыть таблицу
procedure TopofCalc.CloseDoc; begin if DocLoaded then begin try if IsOpenOffice then Document.Dispose; if IsExcel then Document.close; finally //Clean up both "pointer"... Document:= Null; ActiveSheet:= Null; end; end; end;
и само приложение
procedure TopofCalc.CloseProg; begin if DocLoaded then CloseDoc; if ProgLoaded then begin try if IsExcel then Programa.Quit; Programa:= Unassigned; finally end; end; Tipoo:= ttcNone; end;
вынесем последовательности команд создания таблицы в отдельную процедуру конструктора
constructor TopofCalc.CreateTable(MyTipoo: TTipooCalc; MakeVisible: boolean); var i: integer; IsFirstTry: boolean; begin //Close all opened things first... if DocLoaded then CloseDoc; if ProgLoaded then CloseProg; IsFirstTry:= true; for i:= 1 to 2 do begin //Try to open OpenOffice... if (MyTipoo = ttcOpenOffice) or (MyTipoo = ttcNone)then begin Programa:= CreateOleObject('com.sun.star.ServiceManager'); if ProgLoaded then begin Tipoo:= ttcOpenOffice; break; end else begin if IsFirstTry then begin //Try Excel as my second choice MyTipoo:= ttcExcel; IsFirstTry:= false; end else begin //Both failed! break; end; end; end; //Try to open Excel... if (MyTipoo = ttcExcel) or (MyTipoo = ttcNone) then begin Programa:= CreateOleObject('Excel.Application'); if ProgLoaded then begin Tipoo:= ttcExcel; break; end else begin if IsFirstTry then begin //Try OpenOffice as my second choice MyTipoo:= ttcOpenOffice; IsFirstTry:= false; end else begin //Both failed! break; end; end; end; end; //Was it able to open any of them? if Tipoo = ttcNone then begin Tipoo:= ttcError; raise exception.create('TopofCalc.create failed, may be no OpenOffice is installed?'); end; //Add a blank document... fVisible:= MakeVisible; NewDoc; end;
это – создание таблицы «с нуля». откроем существующую
procedure TopofCalc.LoadDoc; var ooParams: variant; begin if FileName='' then exit; if not ProgLoaded then LoadProg; if DocLoaded then CloseDoc; DeskTop:= Unassigned; if IsExcel then begin Document:=Programa.WorkBooks.Add(FileName); Document.visible:=visible; Document:= Programa.ActiveWorkBook; ActiveSheet:= Document.ActiveSheet; end; if IsOpenOffice then begin Desktop:= Programa.CreateInstance('com.sun.star.frame.Desktop'); ooParams:= VarArrayCreate([0, 0], varVariant); ooParams[0]:= ooCreateValue('Hidden', not Visible); Document:= Desktop.LoadComponentFromURL(FileNameToURL(FileName), '_blank', 0, ooParams); ActivateSheetByIndex(1); end; if Tipoo=ttcNone then raise exception.create('File "'+FileName+'" is not loaded. Are you install OpenOffice?'); end;
опишем еще один конструктор для открытия существующей таблицы
constructor TopofCalc.OpenTable(Name: string; MakeVisible: boolean); begin //Store values... FileName:= Name; fVisible:= MakeVisible; //Open program and document... LoadProg; LoadDoc; end;
кроме того, опишем уничтожение объекта
destructor TopofCalc.Destroy; begin CloseDoc; CloseProg; inherited; end;
по аналогии, опишем сохранение
function TopofCalc.SaveDoc: boolean; begin result:= false; if DocLoaded then begin if IsExcel then begin Document.Save; result:= true; end; if IsOpenOffice then begin Document.Store; result:= true; end; end; end;
печать
function TopofCalc.PrintDoc: boolean; var ooParams: variant; begin result:= false; if DocLoaded then begin if IsExcel then begin Document.PrintOut; result:= true; end; if IsOpenOffice then begin //NOTE: OpenOffice will print all sheets with Printable areas, but if no //printable areas are defined in the doc, it will print all entire sheets. //Optional parameters (wait until fully sent to printer)... ooParams:= VarArrayCreate([0, 0], varVariant); ooParams[0]:= ooCreateValue('Wait', true); Document.Print(ooParams); result:= true; end; end; end;
и режим предварительного просмотра
procedure TopofCalc.ShowPrintPreview; begin if DocLoaded then begin Visible:= true; if IsExcel then Document.PrintOut(,,,true); if IsOpenOffice then ooDispatch('.uno:PrintPreview', Unassigned); end; end;
нам также пригодится скрытие/отображение на экране
procedure TopofCalc.SetVisible(v: boolean); begin if DocLoaded and (v<>fVisible) then begin if IsExcel then Programa.Visible:= v; if IsOpenOffice then Document.getCurrentController.getFrame.getContainerWindow.setVisible(v); fVisible:= v; end; end;
теперь, мы можем получить информацию о таблице.
Начнем с количества листов
function TopofCalc.GetCountSheets: integer; begin result:= 0; if DocLoaded then begin if IsExcel then result:= Document.Sheets.count; if IsOpenOffice then result:= Document.getSheets.GetCount; end; end;
и сделаем один из листов активным.
function TopofCalc.ActivateSheetByIndex(nIndex: integer): boolean; begin result:= false; if DocLoaded then begin if IsExcel then begin Document.Sheets[nIndex].activate; ActiveSheet:= Document.ActiveSheet; result:= true; end; //Index is 1 based in Excel, but OpenOffice uses it 0-based if IsOpenOffice then begin ActiveSheet:= Document.getSheets.getByIndex(nIndex-1); result:= true; end; sleep(100); //Asyncronus, so better give it time to make the change end; end;
активным лист можно сделать не только по его индексу, но и по названию
function TopofCalc.ActivateSheetByName(SheetName: string; CaseSensitive: boolean): boolean; var OldActiveSheet: variant; i: integer; begin result:= false; if DocLoaded then begin if CaseSensitive then begin //Find the EXACT name... if IsExcel then begin Document.Sheets[SheetName].Select; ActiveSheet:= Document.ActiveSheet; result:= true; end; if IsOpenOffice then begin ActiveSheet:= Document.getSheets.getByName(SheetName); result:= true; end; end else begin //Find the Sheet regardless of the case... OldActiveSheet:= ActiveSheet; for i:= 1 to GetCountSheets do begin ActivateSheetByIndex(i); if UpperCase(ActiveSheetName)=UpperCase(SheetName) then begin result:= true; Exit; end; end; //If not found, let the old active sheet active... ActiveSheet:= OldActiveSheet; end; end; end;
getByName(string) имеет свойства для чтения и записи
function TopofCalc.GetActiveSheetName: string; begin if DocLoaded then begin if IsExcel then result:= ActiveSheet.Name; if IsOpenOffice then result:= ActiveSheet.GetName; end; end;
procedure TopofCalc.SetActiveSheetName(NewName: string); var ooParams:variant; begin if DocLoaded then begin if IsExcel then Programa.ActiveSheet.Name:= NewName; if IsOpenOffice then begin ActiveSheet.setName(NewName); //This code always changes the name of "visible" sheet, not active one! ooParams:= VarArrayCreate([0, 0], varVariant); ooParams[0]:= ooCreateValue('Name', NewName); ooDispatch('.uno:RenameTable', ooParams); end; end; end;
пригодится проверка на защиту листа от записи
function TopofCalc.IsActiveSheetProtected: boolean; begin result:= false; if DocLoaded then begin if IsExcel then result:= ActiveSheet.ProtectContents; if IsOpenOffice then result:= ActiveSheet.IsProtected; end; end;
добваление листа
procedure TopofCalc.AddNewSheet(NewName: string); var ooSheets: variant; begin if DocLoaded then begin if IsExcel then begin Document.WorkSheets.Add; Document.ActiveSheet.Name:= NewName; //Active sheet has move to this new one, so I need to update the var ActiveSheet:= Document.ActiveSheet; end; if IsOpenOffice then begin ooSheets:= Document.getSheets; ooSheets.insertNewByName(NewName, 1); //Redefine active sheet to this new one ActiveSheet:= ooSheets.getByName(NewName); end; end; end;
перейдем от листов к ячейкам
получить значение ячейки
//OpenOffice start at cell (0,0) while Excel at (1,1) function TopofCalc.GetCellText(row, col: integer): string; begin if DocLoaded then begin if IsExcel then result:= ActiveSheet.Cells[row, col].Formula; //.Text; if IsOpenOffice then result:= ActiveSheet.getCellByPosition(col-1, row-1).getFormula; end; end;
установить значение
procedure TopofCalc.SetCellText(row, col: integer; Txt: string); begin if DocLoaded then begin if IsExcel then ActiveSheet.Cells[row, col].Formula:= Txt; if IsOpenOffice then ActiveSheet.getCellByPosition(col-1, row-1).setFormula(Txt); end; end;
то же самое, но по имени ячейки.
Обязательно указание номера листа function TopofCalc.GetCellTextByName(Range: string): string; var OldActiveSheet: variant; begin if DocLoaded then begin if IsExcel then begin result:= Programa.Range[Range].Text; //Set 'Formula' but Get 'Text'; end; if IsOpenOffice then begin OldActiveSheet:= ActiveSheet; //If range is in the form 'NewSheet!A1' then first change sheet to 'NewSheet' if pos('!', Range) > 0 then begin //Activate the proper sheet... if not ActivateSheetByName(Copy(Range, 1, pos('!', Range)-1), false) then raise exception.create('Sheet "'+Copy(Range, 1, pos('!', Range)-1)+ '" not present in the document.'); Range:= Copy(Range, pos('!', Range)+1, 999); end; result:= ActiveSheet.getCellRangeByName(Range).getCellByPosition(0,0).getFormula; ActiveSheet:= OldActiveSheet; end; end; end; procedure TopofCalc.SetCellTextByName(Range: string; Txt: string); var OldActiveSheet: variant; begin if DocLoaded then begin if IsExcel then begin Programa.Range[Range].formula:= Txt; end; if IsOpenOffice then begin OldActiveSheet:= ActiveSheet; //If range is in the form 'NewSheet!A1' then first change sheet to 'NewSheet' if pos('!', Range) > 0 then begin //Activate the proper sheet... if not ActivateSheetByName(Copy(Range, 1, pos('!', Range)-1), false) then raise exception.create('Sheet "'+Copy(Range, 1, pos('!', Range)-1)+ '" not present in the document.'); Range:= Copy(Range, pos('!', Range)+1, 999); end; ActiveSheet.getCellRangeByName(Range).getCellByPosition(0,0).SetFormula(Txt); ActiveSheet:= OldActiveSheet; end; end; end; а так же – размера шрифта. Можно установить его в шаблоне, а можно прямо в ходе работы программы. procedure TopofCalc.FontSize(row,col:integer;oosize:integer); begin if DocLoaded then begin if IsExcel then begin Programa.ActiveSheet.Cells[row,col].Font.Size:=oosize; end; if IsOpenOffice then begin ActiveSheet.getCellByPosition(col-1, row-1).getText.createTextCursor.CharHeight:= oosize; end; end; end; сделать шрифт жирным procedure TopofCalc.Bold(row,col: integer); const ooBold: integer = 150; //150 = com.sun.star.awt.FontWeight.BOLD begin if DocLoaded then begin if IsExcel then begin Programa.ActiveSheet.Cells[row,col].Font.Bold; end; if IsOpenOffice then begin ActiveSheet.getCellByPosition(col-1, row-1).getText.createTextCursor.CharWeight:= ooBold; end; end; end; изменить ширину столбца procedure TopofCalc.ColumnWidth(col, width: integer); //Width in 1/100 of mm. begin if DocLoaded then begin if IsExcel then begin //Excel use the width of '0' as the unit, we do an aproximation: Width '0' = 2 mm. Programa.ActiveSheet.Cells[col, 1].ColumnWidth:= width/100/3; end; if IsOpenOffice then begin ActiveSheet.getCellByPosition(col-1, 0).getColumns.getByIndex(0).Width:= width; end; end; end; в заключение, предлагаю функции, предназначенные именно для OpenOffice
преобразование имени //Change 'C:\File.txt' into 'file:///c:/File.txt' (for OpenOffice OpenURL) function TopofCalc.FileNameToURL(FileName: string): string; begin result:= ''; if LowerCase(copy(FileName,1,8))<>'file:///' then result:= 'file:///'; result:= result + StringReplace(FileName, '\', '/', [rfReplaceAll, rfIgnoreCase]); end; создание объекта function TopofCalc.ooCreateValue(ooName: string; ooData: variant): variant; var ooReflection: variant; begin if IsOpenOffice then begin ooReflection:= Programa.createInstance('com.sun.star.reflection.CoreReflection'); ooReflection.forName('com.sun.star.beans.PropertyValue').createObject(result); result.Name := ooName; result.Value:= ooData; end else begin raise exception.create('ooValue imposible to create, load OpenOffice first!'); end; end; запуск диспатчера procedure TopofCalc.ooDispatch(ooCommand: string; ooParams: variant); var ooDispatcher, ooFrame: variant; begin if DocLoaded and IsOpenOffice then begin if (VarIsEmpty(ooParams) or VarIsNull(ooParams)) then ooParams:= VarArrayCreate([0, -1], varVariant); ooFrame:= Document.getCurrentController.getFrame; ooDispatcher:= Programa.createInstance('com.sun.star.frame.DispatchHelper'); ooDispatcher.executeDispatch(ooFrame, ooCommand, '', 0, ooParams); end else begin raise exception.create('Dispatch imposible, load a OpenOffice doc first!'); end; end; end.
Формирование структуры HTML-документа
Поскольку TMIDASPageProducer (TCustomMIDASPageProducer) является генератором содержания HTML-документа, в его описание входит интерфейс IWebContent, который, собственно, это содержание и предоставляет. Заголовок соответствующего класса выглядит следующим образом:
TCustomMIDASPageProducer = class(TPageItemProducer, IWebContent, IWebComponentEditor, IScriptEditor)
Помимо IWebContent, в описании класса участвуют еще два интерфейса: IWebComponentEditor и IScriptEditor, которые являются средствами связи с design-time редактором для компонентов типа TWebComponent и HTML-кода. НижДалее приведено краткое описание ключевых свойств TMidasPageProducer.
HTMLDoc. Базовый шаблон, содержащий включения (includes) описателей содержания. HTMLFile. То же, что и HTMLDoc, но с привязкой к файлу. IncludePathURL. Путь к библиотекам JavaScript (в формате URL). Может быть полным (http://someserver/iexpress/) или относительным (/iexpress/). Styles. Описание стандартных стилей для генерации HTML-документа. Аналог файла стилей, используемого при создании канонических веб-страниц. StylesFile. То же, что и Styles, но с привязкой к файлу стилей. WebPageItems. Список специальных компонентов, определяющих ключевые элементы документа. Основные типы PageItem: DataForm, QueryForm и LayoutGroup. Каждый из базовых компонентов TWebPageItem может иметь вложенные компоненты. Например, для DataForm это могут быть DataGrid, DataNavigator и т. д.Компоненты TDataForm, TQueryForm и т. д. определяют структуру и основные параметры отображения HTML-документа, а стили определяются свойствами Styles и HTMLDoc.
Следует отметить, что благодаря тому, что состав HTML-документа определяется стандартными компонентами, поставляемыми в исходных текстах, функциональные возможности InternetExpress становятся практически неограниченными – за счет создания специализированных наборов компонентов для построения интернет-приложений. Примеры подобного подхода есть в демонстрационном приложении InetXCenter из Delphi 5.
Невизуальный компонент TWebActionItem позволяет задать реакцию интернет-приложения на те или иные события, транслируемые протоколом HTTP от веб-клиента. Предоставляя специальные свойства для задания ссылок на компоненты TMIDASPageProducer и TPageProducer, а также URL, TWebActionItem позволяет описать алгоритм перемещения между HTML-документами, составляющими интернет-приложение, реагировать на передачу параметров и значений полей HTML-документа определенным образом и т. д. Создавая обработчик события TWebActionItem.OnAction, программист получает возможность возвращать необходимые данные в полях запросов, устанавливать идентификационные маркеры (cookies) для веб-клиентов, контролировать генерацию содержания HTML-документов и выполнять ряд других операций практически на самом нижнем уровне функционирования интернет-приложения. Далее описаны основные свойства компонента TWebActionItem.
Default. Использование данного компонента как обработчика событий соответствующих типов (свойство MethodType) в тех случаях, когда явно не задан иной обработчик. Из всех компонентов TWebActionItem, присутствующих в контейнере TWebModule, только у одного свойство Default может иметь значение True. DisplayName. Отображение текущего компонента в списке компонента TCustomWebDispatcher. Должно быть уникальным для своего контекста. Enabled. Как и во многих других компонентах, означает разрешение или запрет выполнения связанных с компонентом действий. Если его значение равно False, то соответствующий компонент типа PageProducer не будет генерировать содержимое HTML-документа. MethodType. Определяет HTTP-метод, при вызове которого со стороны веб-клиента будет использован данный компонент. По умолчанию имеет значение mtAny, то есть все доступные методы, но может принимать значения отдельных типов, например mtGet (запрос на получение веб-клиентом содержимого документа); PathInfo. Задает путь к получателю всех сообщений, объекту типа TWebActionItem, в формате URI (Unified Resource Identifier). Позволяет перенаправить очередь сообщений другому компоненту PageProducer или HTML-документу; Producer. Ссылка на компонент PageProducer. Если компонент явно не задан, то для реакции на сообщение обязательно нужно создать обработчик OnAction. Если ссылка на PageProducer актуальна (не nil), сообщение обрабатывается или PageProducer, или обработчиком события OnAction (если он есть).Примеры использования свойств TWebActionItem есть в демонстрационном приложении InetXCenter (модуль InextXCenterModule.pas).
Поговорим теперь о невизуальных компонентах категории PageItems, предназначенных для формирования структуры HTML-документа. Как и компоненты VCL, они делятся на средства отображения типовых элементов HTML-документа и элементов для обработки данных, получаемых от сервера приложений. У каждого из этих компонентов могут быть наследники, расширяющие их свойства или реализующие те элементы HTML, эквивалента которым нет в текущей версии InternetExpress. Компоненты PageItems находятся в модуле miditems.pas. При построении HTML-документа они объединяются в иерархические структуры. Например, компонент TDataNavigator содержит компоненты типа TDataSetButton.
При создании HTML-документа компонентом TMIDASPageProducer эти компоненты генерируют фрагменты HTML-кода, описывающего соответствующие HTML-элементы. Компонент TMIDASPageProducer объединяет их в единый поток и подставляет вместо соответствующих тэгов в шаблоне документа. К элементам HTML “привязываются” обработчики событий, написанные на JavaScript и являющиеся аналогами обработчиков событий для визуальных компонентов Delphi, таких как OnClick. Отдельные компоненты PageItems позволяют напрямую задать получателя сообщений (target) в формате URI (свойство Action), что дает возможность переходить от одного HTML-документа к другому и передавать между этими документами параметры в формате протокола HTTP.
Благодаря использованию в TMIDASPageProducer шаблонов для генерации HTML-документов появляется возможность создавать визуальные и невизуальные элементы HTML-документа прямым редактированием. Используя обработчики HTTP-событий, можно связывать такие элементы с генерируемыми шаблоном через компоненты TWebActionItem или при помощи создаваемых опять-таки прямым редактированием обработчиков на JavaScript внутри HTML-документа.
Компонент TXMLBroker передает пакеты данных в формате XML от сервера приложений к HTML-клиенту, получает от HTML-клиента измененные данные, расшифровывает разностные пакеты данных XML и передает сведения об изменении данных на сервер приложений. Этот компонент находится в модуле xmlbrokr.pas.
Компонент TXMLBroker можно использовать в приложении, которое одновременно является и MIDAS-клиентом, и серверным веб-приложением. Серверы такого класса, как правило, имеют две основные функции:
получать от сервера приложений через интерфейс IAppServer пакеты XML-данных; обрабатывать поступающие от браузеров HTTP-сообщения, содержащие пакеты XML-данных с изменениями исходного набора и передавать их серверу приложений.Для того чтобы сделать информацию, содержащуюся в базе данных, доступной в формате XML, достаточно добавить компонент TXMLBroker в контейнер WebModule совместно с компонентом TMIDASPageProducer, который будет использовать XML-пакеты данных для создания HTML-страниц.
TXMLBroker автоматически регистрируется в веб-модуле (или веб-диспетчере) как автодиспетчеризуемый объект (auto-dispatching object). Это означает, что веб-модуль или веб-диспетчер будут перенаправлять все входящие HTTP-сообщения прямо к нему. Все входящие сообщения считаются данными для обновления, порождаемыми браузером в ответ на получение HTML-потока, порождаемого компонентом TApplyUpdatesButton. TXMLBroker автоматически передает пакет с XML-данными, содержащий сведения о различиях в данных, на сервер приложений и возвращает все ошибки, возникшие при обновлении данных, тому компоненту управления содержимым документа (TMIDASPageProducer), который имеет возможность генерации соответствующего ответного сообщения. Среди основных свойств компонента нужно выделить следующие.
AppServer. Интерфейс IAppServer для связи с провайдерами данных. MaxErrors. Максимальное число ошибок, по достижении которого провайдер должен прекратить обновление данных. MaxRecords. Управляет формированием пакетов данных XML. Значение -1 разрешает передачу всех записей из набора данных в XML-пакет; значение 0 разрешает передачу только метаданных; положительное значение определяет число записей (строк), которые могут быть переданы в XML-пакет. Params. Список параметров, передаваемых серверу приложений. Используется, в частности, для передачи параметров хранимых процедур и SQL-запросов. ProviderName. Имя провайдера данных. ReconcileProducer. Ссылка на компонент TReconcilePageProducer, который будет использоваться для разрешения конфликтов данных при обновлении. WebDispatch. Список типов сообщений протокола HTTP, на которые будет реагировать компонент. Как правило, эти сообщения порождаются при нажатии на HTML-странице кнопки типа TApplyUpdatesButton.InternetExpress вблизи
Что же позволяет делать InternetExpress?
На вкладке панели компонентов InternetExpress расположены две пиктограммы, соответствующие двум компонентам базового набора: TXMLBroker и TMIDASPageProducer.
Первая из них “отвечает” за формирование XML-пакета. Также в ее функции входят реакция на изменение данных и оповещение о действиях, выполняемых клиентом. TMIDASPageProducer “отвечает” за формирование сборного DHTML-документа. Последний, собственно, и является клиентским приложением, поскольку содержит все те визуальные элементы, соответствующие структуре пакета данных XML. В этот документ передаются XML-пакеты, формируемые компонентом XMLBroker.
В тот момент, когда от клиентского приложения на сервер приложений приходит сообщение о необходимости изменить информацию, TMIDASPageProducer опрашивает все элементы управления HTML, формирует пакет с данными, подлежащими обновлению, и передает их на сервер приложений. Таким образом, обработка данных на клиенте происходит с использованием средств HTML, а передача структурированных данных к клиенту и изменений от него -- при помощи пакетов данных XML.
Эти компоненты помещаются в веб-модуль (WebModule) серверного приложения, для создания которого может быть использован специальный мастер (для этого нужно выбрать команду File -> New, а затем щелкнуть на пиктограмме Web Server Application).
WebModule является наследником TDataModule. По сравнению с “родителем” он обладает некоторыми дополнительными возможностями, которые позволяют обмениваться данными с веб-клиентами. Кроме базового набора InternetExpress, есть еще несколько компонентов, таких как TReconcilePageProducer, которые устанавливаются из дополнительных пакетов, входящих в комплект поставки Delphi. Естественно, существует возможность наследования базовых классов и создания на их основе собственных компонентов с расширенными возможностями.
Компонент TMIDASPageProducer отвечает за сборку HTML-документа, отображающего “живой” набор данных, получаемый от сервера приложений, или же от “типового” HTML-документа, вообще не обрабатывающего данные. Компонент может быть использован для создания веб-приложений на основе MIDAS, которые будут отображать информацию, получаемую из БД через сервер приложений, и передавать ее HTML-клиентам в пакетах XML-данных. При создании веб-модуля в соответствующих элементах TWebActionItem должна быть поставлена ссылка на один из таких компонентов (свойство Producer).
TMIDASPageProducer создает HTML-документ на основе шаблона. В отличие от других компонентов типа Producer, он имеет стандартный (default) шаблон, в котором содержатся несколько описаний верхнего уровня, на основе которых в других компонентах порождаются HTML-документы. Помимо шаблонов, содержание конечного документа может определяться данными, порождаемыми другими компонентами веб-модуля, другим компонентом TMIDASPageProducer через свойство TMIDASPageProducer.Content и т. д.
Связывание HTML-элементов с пакетами данных XML и обработчиками событий HTTP в TMIDASPageProducer осуществляется исключительно по именам HTML-объектов и соответствующих событий. Это позволяет редактировать сгенерированный HTML-шаблон в любом редакторе (специализированным для работы с HTML или нет), придавая ему необходимый внешний вид и дополняя логику обработки данных вставками JavaScript. Даже если свойства объектов, порожденных встроенным редактором TMIDASPageProducer, будут изменены другими средствами, эти изменения не будут потеряны, поскольку будут включены в шаблон.
Расширение функциональности обработчика шаблонов (свойство TMIDASPageProducer.HTMLdoc) возможно за счет реализации обработчика события TMIDASPageProducer.OnHTMLtag или перекрытия метода TMIDASPageProducer.DoTagEvent. Реализовав собственную версию обработчика этого события, программист получает возможность использовать в теле шаблона документа собственные тэги, заменяя их на этапе генерации HTML-документа соответствующими значениями. Пример такого подхода показан в демонстрационном приложении InetXCenter из состава Delphi 5 (модуль InetXCenterProd.pas).
Конечно, возможности InternetExpress можно расширять практически неограниченно, разрабатывая специальные компоненты-наследники класса TMIDASPageProducer и компонентов, используемых для формирования содержимого документа (TDataForm, TQueryForm и др.). Создавая на их основе специализированные компоненты, можно максимально упростить создание конечного решения на основе InternetExpress, реализуя специфические возможности, необходимые тому или иному интернет-приложению. Например, в демонстрационном приложении InetXCenter создание наследника компонента TMIDASPageProducer позволило реализовать такие возможности, как генерация полей заголовка HTML-документа , комментарии и описания, автоматически подставляемые в конечный HTML-документ, и другие расширения базового компонента.
Клиентская часть приложения InternetExpress
Клиентская часть приложения на основе InternetExpress представляет собой собственно HTML-документ, порожденный одним или несколькими компонентами TMIDASPageProducer (или их наследниками), интерпретируемый тем или иным браузером. Как уже говорилось, этот документ может содержать элементы отображения и управления, соответствующие структуре пакета данных XML. К ним также могут добавляться элементы управления, формирующие HTML-аналог DBnavigator из состава Delphi VCL, если соответствующие параметры были заданы при настройке PageProducer, а также другие элементы управления HTML, как связанные с обработкой данных, так и образующие независимые части интерфейса, например группу для ввода имени пользователя и пароля.
Приложение InternetExpress работает следующим образом. Браузер обращается по ссылке (URL) к серверному приложению InternetExpress. Оно возвращает HTML-документ, который можно рассматривать как некую отправную точку в процессе обработки.
По запросу пользователя серверное приложение сначала возвращает очередной HTML-документ, содержащий (при необходимости) ссылки на библиотеки JavaScript, отвечающие за обработку XML-пакетов. Затем уже переданный пользователю документ посылает запрос серверной части приложения, которая возвращает клиенту данные в виде XML-пакетов, интерпретируемых соответствующими библиотеками JavaScript.
После того как пользователь просмотрит набор данных и, при необходимости, внесет в них изменения, он может передать изменения серверной части приложения. Этот процесс запускается событием, которое, как правило, связано с элементом управления -- кнопкой (например, Submit) и передается серверной части приложения InternetExpress, а именно компоненту TMIDASPageProducer. Все сведения об изменении данных передаются серверной части приложения в виде разностных пакетов XML (XML delta packets).
Серверная часть получает информацию об изменении данных и использует сервер приложений для внесения этих изменений в БД. В случае возникновения конфликта (reconcile error) имеется возможность сформировать HTML-вариант Reconcile Dialog из состава Delphi.
Передача данных в интернет при помощи InternetExpress
Сергей Кривошеев,
InternetExpress - это входящее в состав Borland Delphi 5 интересное средство обработки и публикации данных в интернет, основанное на технологии MIDAS. В Delphi имеется набор компонентов, позволяющих реализовать полный цикл клиент-серверной обработки данных на базе интернет с применением как средств создания приложений на основе ISAPI/NSAPI, ASP и CGI, так и новых технологий, к примеру, стандарта XML.
В InternetExpress используются средства поддержки XML из MIDAS 3. Поскольку в настоящее время не все интернет-браузеры поддерживают представление данных по стандарту XML, в InternetExpress реализована специальная технология поддержки XML на основе JavaScript и DHTML, позволяющая использовать InternetExpress браузерами, не поддерживающими XML. Кроме того, если приложение InternetExpress работает с IE 5, то порождаемый им XML-пакет будет специальным образом оптимизироваться. В браузерах без такой поддержки пакеты данных XML разбираются с использованием специального модуля JavaScript (xmldom.js), который реализует спецификацию DOM (Document Object Model).
Объектная модель XML-документов представляет его внутреннюю структуру в виде совокупности определенных объектов. Для удобства эти объекты организуются в древообразную структуру данных: каждый элемент документа может быть отнесен к отдельной ветви, а все его содержимое - в виде набора вложенных элементов, комментариев, секций CDATA и т. д. представляется в этой структуре поддеревьями. Поскольку в любом правильно составленном XML-документе обязательно есть главный элемент, то все его содержимое можно представит в виде поддеревьев этого основного элемента, называемого в данном случае корнем дерева документа.
Объектное представление структуры документа не является для разработчиков чем-то новым. Объектно-ориентированный подход давно используется в сценариях для доступа к содержимому HTML-страницы. Доступные для JavaScript или VBScript элементы веб-страницы и раньше можно было создавать, просматривать и редактировать при помощи соответствующих объектов. Но их список и набор методов постоянно изменяется и зависит от типа браузера и версии языка. Для того, чтобы обеспечить интерфейс доступа к содержимому структурированного документа, не зависящий от языка программирования и типа документа, консорциумом W3 была разработана и официально утверждена спецификация объектной модели DOM Level 1.
DOM - это спецификация универсального платформо- и программно-независимого доступа к содержимому документов. Она является просто своеобразным API для их обработчиков. DOM служит стандартным способом построения объектной модели любого документа HTML или XML, при помощи которой можно производить поиск нужных фрагментов, создавать, удалять и модифицировать отдельные элементы.
Для описания интерфейсов доступа к содержимому XML-документов в спецификации DOM применяется платформонезависимый язык IDL (Interface Definition Language). Для использования этих интерфейсов их необходимо “перевести” на какой-то конкретный язык программирования. Однако этим занимаются создатели самих анализаторов. Нам можно ничего не знать о способе реализации интерфейсов -- с точки зрения разработчиков прикладных программ DOM выглядит как набор объектов с определенными методами и свойствами.
Серверная часть приложения InternetExpress
Серверная часть интернет-приложения, созданного на основе InternetExpress, состоит из исполняемого модуля, написанного в данном случае на Delphi 5 и включающего в себя WebModule, а также файлов-библиотек JavaScript, которые, если браузер не поддерживает XML, передаются клиенту. НижДалее перечислены эти библиотеки.
xmldom.js. XML-парзер, соответствующий стандарту DOM (Document Object Model), написанный на JavaScript. Позволяет браузерам без встроенной поддержки XML использовать пакеты данных этого стандарта. Для IE5 этот файл не передается, а XML-пакет оптимизируется специальными образом.
xmldb.js. Библиотека классов доступа к данным, обслуживающая пакеты данных XML. xmldisp.js. Библиотека с описаниями связей между классами доступа к данным в xmldb.js и элементами HTML. xmlerrdisp.js. Библиотека классов для обработки конфликтных ситуаций, возникающих при изменении данных. Использует пакет разности данных (XML delta packet) и пакет ошибок (XML error packet); xmlshow.js. Библиотека функций для отображения окон с данными XML.Для того чтобы передать эти библиотеки клиенту и использовать их там, достаточно включить в HTML-документ ссылки на них
Ссылка на xmldom.js требуется только в том случае, если браузер не имеет встроенной поддержки XML.
Создание веб-приложения на основе InternetExpress
Как же построить веб-приложение на основе InternetExpress?
Для создания веб-приложения необходим скомпилированный и зарегистрированный сервер данных. В данном примере используются данные из таблицы biolife.db, входящей в состав демонстрационной базы данных из комплекта Delphi 5. Данные публикуются через контейнер Remote Data Module.
Контейнер Remote Data Module
После создания и регистрации сервера данных необходимо создать клиента для этого сервера, который, в свою очередь, будет сервером для HTML-клиента. Для создания расширений веб-сервера в Delphi 5 есть специальный “мастер”. Он может быть вызван через меню File -> New -> Web Server Application.
В данном случае мы создаем CGI-приложение, выводящее порождаемый поток данных в устройство стандартного вывода (stdout). Поток данных этого приложения будет без изменений передаваться вызывающему документу через транспортный протокол.
Мастер автоматически создаст контейнер типа TWebModule, в который необходимо поместить компоненты TMIDASPageProducer и TXMLBroker. Сюда же мы поместим и компонент TDCOMConnection, который будем использовать для подключения к удаленному серверу данных, а также компонент TClientDataSet для доступа к удаленному модулю данных.
Определив необходимые для соединения с удаленным сервером свойства, переходим к созданию содержимого HTML-документа. Для этого необходимо назначить для объекта класса TXMLBroker свойства RemoteServer и ProviderName, а также создать хотя бы один компонент TWebActionItem, вызвав соответствующий редактор с помощью контекстного меню компонентов TXMLBroker и TMIDASPageProducer.
В примере используется только один такой компонент, свойству которого Default присвоено значение True, за счет чего все сообщения HTTP будут поступать на этот компонент, а от него -- на TXMLBroker и TMIDASPageProducer.
Далее необходимо вызвать редактор веб-страниц. Это можно сделать с помощью команды Web Page Editor контекстного меню компонента TMIDASPageProducer. Для работы этого элемента необходим Microsoft Internet Explorer 4.0 и выше.
После добавления необходимых элементов получаем готовое к применению приложение веб-сервера. При установке параметров отображения HTML-документа можно воспользоваться свойствами компонента DataGrid и других элементов HTML-документа для придания ему необходимого внешнего вида, а также вручную доработать HTML-код в соответствующем встроенном редакторе.
После компиляции исполняемый модуль (в нашем примере - XMLServerApp.exe) необходимо поместить в каталог веб-сервера, для которого выделены права на запуск приложений. В этот же каталог необходимо поместить библиотеки JavaScript. Для проверки правильности размещения библиотек можно воспользоваться специальным HTML-файлом scripttest.HTML, который находится в каталоге Demos\Midas\InternetExpress\TroubleShoot на компакт-диске Delphi 5 или в каталоге установки на жестком диске рабочей станции. Этот HTML-файл проверяет правильность размещения библиотек и настройки веб-сервера и в случае наличия тех или иных ошибок выдает некоторые рекомендации по разрешению проблем.
По окончании настройки можно обратиться к нашему приложению напрямую через протокол HTTP, поскольку оно порождает полноценный HTML-документ, не требующий дополнительной “обвязки”.
Рассматриваемое в рамках данной статьи демонстрационное приложение отнюдь не претендует на полноту и законченность. Для более полного ознакомления с возможностями InternetExpress я рекомендую обратиться к демонстрационным примерам из поставки Delphi 5 Enterprise, находящимеся в каталоге Runimage\Delphi50\Demos\Midas\InternetExpress на компакт-диске или в Demos\Midas\InternetExpress, расположенном в том каталоге на жестком диске, где находится Delphi 5. Внимательно прочитайте сопроводительные файлы к этим примерам, поскольку некоторые из них требуют специфических настроек Delphi и/или веб-сервера.
document.write(''); Новости мира IT:
02.08 - 02.08 - 02.08 - 02.08 - 02.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 31.07 - 31.07 - 31.07 - 31.07 - 31.07 -
Новости мира IT:
02.08 - 02.08 - 02.08 - 02.08 - 02.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 31.07 - 31.07 - 31.07 - 31.07 - 31.07 -
Архив новостей
Последние комментарии:
(66)2 Август, 17:53 (19)
2 Август, 17:51 (34)
2 Август, 15:40 (42)
2 Август, 15:35 (1)
2 Август, 14:54 (3)
2 Август, 14:34 (3)
2 Август, 14:15 (2)
2 Август, 13:34 (7)
2 Август, 13:04 (3)
2 Август, 12:28
BrainBoard.ruМоре работы для программистов, сисадминов, вебмастеров.
Иди и выбирай!
Loading
google.load('search', '1', {language : 'ru'}); google.setOnLoadCallback(function() { var customSearchControl = new google.search.CustomSearchControl('018117224161927867877:xbac02ystjy'); customSearchControl.setResultSetSize(google.search.Search.FILTERED_CSE_RESULTSET); customSearchControl.draw('cse'); }, true);
|
|
| IT-консалтинг | Software Engineering | Программирование | СУБД | Безопасность | Internet | Сети | Операционные системы | Hardware |
| PR-акции, размещение рекламы — , тел. +7 495 6608306, ICQ 232284597 | Пресс-релизы — |
|
|
|
| This Web server launched on February 24, 1997 Copyright © 1997-2000 CIT, © 2001-2009 |
|
|
| Внимание! Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав. |
|
Предлагаем на любой вкус и цвет! |
К материалу прилагаются файлы:
(196 K) обновление от 5/12/2006 7:10:00 AM (10 K) обновление от 5/12/2006 7:10:00 AM
Методы нахождения базового маршрута
Метод 1.1 («жадный», Greedily). Сначала на графе, образованном матрицей А, отыскивается и включается в маршрут вершина (город) T[k] , которая ближе всех к начальной. Далее отыскивается самая близкая к T[k] из числа еще не включенных в маршрут и т. д. В результате получается приближенное решение задачи – базовый маршрут.
Метод 1.2 («деревянный», Woody). Сначала в маршрут включаются две вершины начальная T[0] и конечная T[N-1]. Далее отыскивается вершина, которая характеризуется наименьшим расстоянием D(T[i]+T[k]) + D(T[k]+T[j]) — D(T[i] + T[j]), где i = 0, j = N-1, k – номера еще не включенных в маршрут вершин. Найденная вершина помещается в маршрут (0, k, N-1). На следующем шаге отыскивается вершина L, которая характеризуется наименьшим расстоянием DL от звена (0, k), и вершина M, имеющая наименьшее расстояние DM от звена (k, N-1). Среди L и M выбирается та, которая имеет наименьшее из DL и DM, и включается внутрь своего звена (0, k) или (k, N-1). Пусть это вершина M с номером m. Теперь маршрут состоит из трех звеньев (0, k), (k, m), (m, N-1). Процесс продолжается до тех пор, пока есть не включенные в маршрут вершины.
Метод 1.3 (простейший, Simply). Промежуточные вершины в маршрут включаются случайным образом. В частности, базовым будет допустимый маршрут G[i] = i.
Маршруты, построенные этими методами, вычисляются с очень высокой скоростью (практически мгновенно). Однако длина этих маршрутов в подавляющем большинстве случаев далека от практически приемлемой. Для этих целей применено несколько методов улучшения базового маршрута.
Методы улучшения базового маршрута
Метод 2.1 (перестановок, Permutations). Совершается последовательный проход по парам соседних вершин всех звеньев с перестановкой этих вершин. Если перестановка уменьшает длину маршрута, то этот маршрут считается текущим. Производятся новые попытки улучшить его тем же методом до тех пор, пока перестановки не дадут эффекта. Далее аналогичным образом выполняются перестановки по трем соседним вершинам из числа тех, которые не попали в число ранее проведенных операций с двумя соседними вершинами (перестановки более широкого диапазона, т. е. по 4 и более, не выполнялись). Эксперименты с графами показали, что процедура улучшения маршрута при помощи перестановок достаточно эффективна и быстродействие ее весьма высоко.
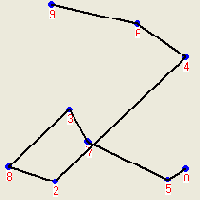
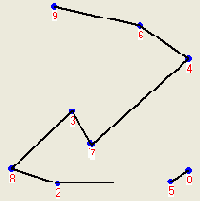
Метод 2.2 (удаление петлей, CrossDeleting). Часто текущий маршрут содержит петли. Например, на рисунке 1 цепочка вершин 5-7-3-8-2-4 образуют петлю. Петля начинается с левой по ходу маршрута вершины отрезка 5-7 и заканчивается правой вершиной отрезка 2-4. Существование петли определяется наличием пересекающихся отрезков маршрута. Если внутреннюю цепочку петли повернуть в противоположном направлении, то есть заменить указанную цепочку на 5-2-8-3-7-4, то петля исчезнет (рисунок 2), а маршрут станет короче. Метод отличается чрезвычайно высоким быстродействием и высокой эффективностью.
 |
 |
|
| Рисунок 1.Маршрут с петлей | Рисунок 2. Улучшенный маршрут |
Метод 2.3 (разворот цепочек, ChainTurnings). Как показали эксперименты, отсутствие петлей еще не означает, что процедура разворота цепочек без петлей неэффективна. Для оптимизации текущего маршрута применялась процедура разворота всех возможных цепочек. Метод имеет самое низкое быстродействие в сравнении с другими методами улучшения. Поэтому на практике его применяли для цепочек с числом звеньев не более шести.
Метод 2.4 (комбинированный, CorrectPath). После нахождения какого-нибудь базового маршрута G к нему применялась комбинированная процедура улучшения по методам 2.1 – 2.3. Хотя метод 2.2 является частным случаем метода 2.3, его все равно применяли из-за высокого быстродействия и способности к эффективному разворота цепочек из любого числа звеньев. Метод имеет код: procedure CorrectPath(N: Integer; var G: TIntVec; var Path: Integer); begin repeat until not Permutations(N,G) and not ChainTurnings(N,G) and not CrossDeleting(N,G) and not MoveTops(N,G); Path:= PathByG(N,G); // расчет длины маршрута end;
Приближенные комбинированные методы нахождения кратчайшего маршрута
Применив три метода , , расчета базового маршрута и комбинированный метод их улучшения, получили три приближенных метода расчета маршрута:
метод 3.1: procedure GreedilyCorrect(N: Integer; var G: TIntVec; var Path: Integer); begin Greedily(N,G); CorrectPath(N,G,Path); end;
метод 3.2: procedure WoodyCorrect(N: Integer; var G: TIntVec; var Path: Integer); begin Woody(N,G); CorrectPath(N,G,Path); end;
и метод 3.3: procedure SimplyCorrect(N: Integer; var G: TIntVec; var Path: Integer); begin Simply(N,G); CorrectPath(N,G,Path); end;
В экспериментах с методами 3.1–3.3 установлено, что ни один из них не является предпочтительным. В зависимости от матрицы А лучший результат с равной вероятностью мог дать любой из этих методов (интересно, что даже простейший базовый маршрут G[i] = i после улучшений нередко трансформировался в самый короткий маршрут, что свидетельствует о том, что решение задачи практически не зависит от выбора базового маршрута). Поэтому в качестве рабочего применяли комбинированный метод 3.4 (комбинация всех), суть которого состоит в последовательном применении методов 3.1–3.3 к матрице А с последующим выбором лучшего маршрута среди сформированных этими методами.
Для того чтобы можно было оценить точность приближенной методики разработана рекурсивная процедура (RecoursiveMethod), позволяющая получить точное решение задачи переборным методом. Для повышения быстродействия в процедуру внесены некоторые очевидные эвристические усовершенствования. Процедура позволила получить точное решение за приемлемое для проведения необходимых оценок время (до 5 минут на вариант размещения городов) при N<23.
Для оценки точности метода при больших значениях N (N>22) процедуру RecoursiveMethod применить нельзя, поэтому составлена процедура Rand многократного применения метода к одной и той же матрице А с различными случайными базовыми маршрутами. Процедура последовательно формирует маршруты до тех пор, пока последний лучший маршрут не повторится 5 раз подряд. Нельзя сказать, что такой способ позволяет найти самый короткий маршрут. Однако результаты работы процедуры дают интуитивную уверенность в том, что сравнение «быстрого» результата с результатом длительной работы метода имеет достаточно высокую вероятность корректности за неимением точных методов. Уверенность в этом подкреплена весьма важным выводом, который получен после обработки сотен различных матриц для N<23. Он состоит в полном совпадении результатов, полученных с использованием точной процедуры RecoursiveMethod и приближенной Rand (т. е. для данных N процедура Rand всегда находила точное решение задачи).
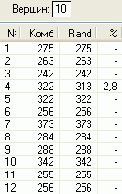
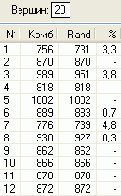
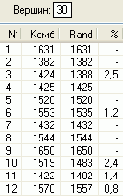
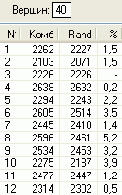
Скриншот интерфейса разработанной в среде Delphi 6 программы показан на .
В качестве примера на рисунке представлен кратчайший маршрут из вершины 0 в вершину 13 (N = 14) для матрицы расстояний, которая показана на рисунке 4.
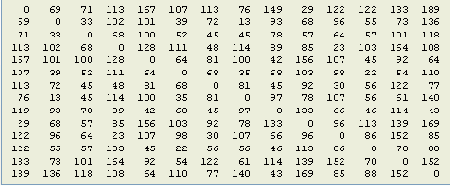
Рисунок 4. Матрица расстояний
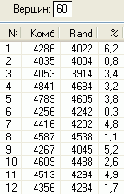
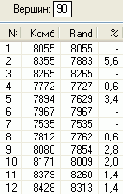
На рисунках 5-10 показаны результаты расчета маршрутов и их протяженности (Комб и Rand) для случайного расположения городов при помощи быстрой процедуры комбинированного метода и процедуры Rand. В последней колонке таблиц приведена процентная погрешность метода , которую рассчитывали по формуле 100 (Комб-Rand)/Комб, %.
 |
 |
 |
||
| Рисунок 5 | Рисунок 6 | Рисунок 7 | ||
 |
 |
 |
||
| Рисунок 8 | Рисунок 9 | Рисунок 10 |
В результате экспериментов с несколькими сотнями матриц расстояний для различных N, получены данные, которые свидетельствуют, что независимо от количества N городов погрешность метода никогда не превосходила 8% при N<101. Средняя погрешность составила 2%, что вполне приемлемо для практики.
На основании обработки многочисленных расчетных данных получена формула ориентировочной оценки быстродействия метода . Среднее время t (с) расчета на компьютере с процессором Intel 1400 кратчайшего маршрута с N городами составило 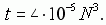
Так, для N = 100 среднее время расчета маршрута составляет 4 секунды. Для практически используемых N<31 это время не превосходит 0,1 с.
Хорошо известна следующая задача. Имеется
Хорошо известна следующая задача. Имеется N городов T[0] .. T[N-1]. Расстояние между каждой парой T[i], T[j] определяется длиной соединяющего их отрезка
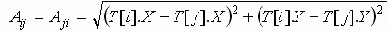
где А – матрица расстояний между городами. Необходимо указать кратчайший маршрут, который начинается городом T[0], проходит через города T[1] .. T[n-2] и заканчивается городом T[N-1].
В теоретическом плане задача решается легко: достаточно перебрать все перестановки городов T[1] .. T[n-2] на маршруте и выбрать ту из них, которая доставляет кратчайший путь. Однако этот метод при существующих возможностях ПК дает результат за приемлемое время вычислений (от нескольких секунд до минуты), если N<10. С дальнейшим увеличением N быстродействие комбинаторного метода быстро снижается и его нельзя использовать в практических расчетах.
Среди других методов решения подобных практических задач (к ним, в частности, можно отнести близкую к рассматриваемой задачу коммивояжера) обычно используют единственный альтернативный метод ветвей и границ (МВГ). Считается, что он обеспечивает точное решение за минимальное время вычислений. Метод, действительно, хорошо работает на "учебных" примерах, однако, как показали эксперименты с МВГ на практических (логистических) примерах решения рассматриваемой задачи, его быстродействие сильно зависит от вида матрицы А и в большинстве случаев МВГ не гарантирует результативности в приемлемое время даже при N=15.
При всей известности задачи не удалось ни в научной литературе, ни в Интернет найти быстрых методов, которые позволили бы приближенно решить задачу с достаточной для практики точностью до 10% за приемлемое время.
Ниже рассмотрено несколько сравнительно быстрых приближенных эвристических методов решения задачи, которые удовлетворяют упомянутому условию. Методы реализуют процессы поиска базового маршрута и последующего его улучшения. При их описании использованы терминология теории графов и средства языка Object Pascal среды Delphi.
Создание сводного отчета в Excel
Владимир Федченко,
В списке обсуждаемых тем на Круглом столе Королевства Delphi часто возникает вопрос о построении сводных таблиц. Сводная таблица представляет собой очень удобный инструмент для отображения и анализа данных, возвращаемых запросом к базе данных. Можно, конечно, для этой цели использовать различные пакеты для построения отчетов (вроде FastReport). Но с генераторами отчетов возникает масса вопросов (отсутствие каких либо библиотек, проблемы с экспортом, отсутствие необходимой документации и т.д.). А начальник требует выдать ему отчет приблизительно такого вида: чтобы были видны все продажи, по всем сотрудникам, по всем регионам, по всем товарам за указанный период времени (скажем, за два года), но денег на покупку генератора отчетов не дает. А как бы было хорошо выдать что-нибудь типа вот такой формы:
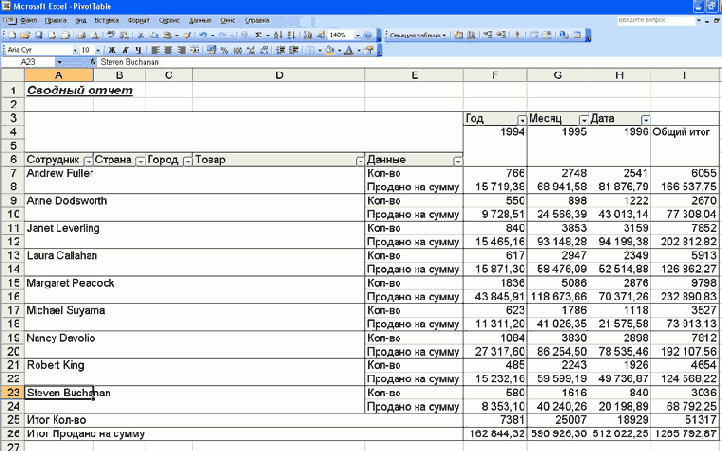
Что тут остается делать. Варианта только два: либо пытаться создавать что-то свое, либо увольняться. Альтернативное решение проблемы предоставлено фирмой Microsoft уже очень давно. Называется оно PivotTable (Сводная таблица) и доступно в меню "Данные" приложения Excel. Осталось только научиться пользоваться этой возможностью. Для этого нам понадобиться:
Delphi 7 (проект создан именно в этой версии); Установленный M$ Excel; Учебная база M$ Access Norhwind.mdb (прилагается в архиве); Немного свободного времени; Много желания понять как это делается.Итак, начинаем. Существует два типа связи с Excel - раннее и позднее. Об их отличиях речь неоднократно шла на Королевстве. Будем использовать раннее связывание, т.к. при позднем компьютер впадает в состояние комы. О том как подключиться к Excel и добавить книгу подробно описано в материалах Королевства. Объявим следующие переменные:
WB:_WorkBook;//рабочая книга WS:_WorkSheet;//лист Excel куда помещается сводная таблица PC:PivotCache;//кеш для данных сводной таблицы PT:PivotTable;//собственно сама сводная таблица i:byte; Отключим реакцию Excel на события (для ускорения работы): XLS.EnableEvents:=False; После предварительной подготовки создаем сводный отчет. Для этого необходимо создать кэш для хранения данных: PC:=WB.PivotCaches.Add(xlExternal,emptyparam)Этот метод имеет два параметра SourceType и SourceData. Но так как мы используем внешние данные (SourceType = xlExternal), то второй параметр нужно оставить пустым. Кэш создан, но не подключен к источнику данных. Надо восполнить этот пробел. Укажем строку подключения, тип подключения и зададим сам запрос:
PC.Connection:=Format('OLEDB;Provider=Microsoft.Jet.OLEDB.4.0;Data Source=%snorthwind.mdb', [ExtractFilePath(ParamStr(0))]); В строке подключения указываем, что база данных находится в одном каталоге с проектом. PC.CommandType:=xlCmdSQL; PC.CommandText:='select salesperson, country, city, productname,'+ 'orderdate, year(orderdate) as yy, month (orderdate) as mm, '+ 'quantity, extendedPrice from invoices';Данные определены и находятся практически в боевой готовности. Попытаемся их визуализировать. Как говорилось выше, визуализировать будем в PivotTable. Для начала создадим сводную таблицу, привязав ее к кэшу с данными, и получим ссылку на интерфейс. Делается это все очень элегантно:
PT:=PC.CreatePivotTable(WS.Range['A3',emptyparam], 'PivotTable1',emptyparam,xlPivotTableVersionCurrent).Три заданных параметра означают следующее: ячейка в которую поместим сводную таблицу, имя сводной таблицы и версия сводной таблицы (зависит от установленной версии M$ Office, в данном случае установлена текущая версия). Пустой параметр называется ReadData. Он указывает на то, читать ли в кэш все данные из внешнего источника (нам это не надо). Вот шаблон и готов. Но что такое шаблон без данных?
В сводной таблице существует несколько типов полей данных: поля колонок, поля строк, поля данных, поля страниц (в данной статье не рассматриваются).
Надо их разместить. Начнем с полей (колонок) таблицы. Тут стоит оговориться, что Excel имеет ограничения на количество полей на одном листе (255). Поскольку данные берутся из базы за период в три года, то количество полей будет существенно больше этого ограничения. Отсюда ясно, почему в запросе был выделен год и месяц. Наши данные будут группироваться сначала по году, затем - по месяцу, затем - по дате. Для того чтобы не возникло ошибки в связи в вышеуказанным ограничением будем прятать детализацию для каждого уровня группировки в цикле по всем полям детализации (кроме последнего, т.к. детализация по нему не предусмотрена):
with (PT.PivotFields('yy') as PivotField) do begin Caption:='Год'; Orientation:=xlColumnField; for i:=1 to PivotItems(emptyparam).Count do PivotItems(i).ShowDetail:=False; end; with (PT.PivotFields('mm') as PivotField) do begin Caption:='Месяц'; Orientation:=xlColumnField; for i:=1 to PivotItems(emptyparam).Count do PivotItems(i).ShowDetail:=False; end; with (PT.PivotFields('orderdate') as PivotField) do begin Caption:='Дата'; Orientation:=xlColumnField; end;Аналогично заполним строки. В них ограничения составляют 65535 записей на лист. По этой причине можно не сворачивать детализацию:
with (PT.PivotFields('salesperson') as PivotField) do begin Caption:='Сотрудник'; Orientation:=xlRowField; end; with (PT.PivotFields('country') as PivotField) do begin Caption:='Страна'; Orientation:=xlRowField; end; with (PT.PivotFields('city') as PivotField) do begin Caption:='Город'; Orientation:=xlRowField; end; with (PT.PivotFields('productname') as PivotField) do begin Caption:='Товар'; Orientation:=xlRowField; end; Осталось поместить сами данные в отчет: PT.AddDataField(PT.PivotFields('quantity'),'Кол-во',xlSum); with PT.AddDataField(PT.PivotFields('extendedPrice'),'Продано на сумму',xlSum) do begin //слегка отформатируем вывод суммы на экран if not XLS.UseSystemSeparators then NumberFormat:='#'+XLS.ThousandsSeparator+'##0'+XLS.DecimalSeparator+'00' else NumberFormat:='#'+ThousandSeparator+'##0'+DecimalSeparator+'00'; end; Ну и наконец, вернем к жизни сам Excel. PT.ManualUpdate:=True;Вот, собственно, и все. Осталось нажать кнопочку F9, немного подождать и порадовать начальника новой формой отчета. Пусть сидит и забавляется. Стоит отметить, что данный отчет абсолютно независим от данных из БД, т.к. все, что вернул запрос, храниться в самой книге Excel. Отчет можно отправить по сети, по электронной почте или перенести любым доступным способом. Сворачивать/разворачивать детализацию по дате можно двойным кликом по данным колонки/строки (только не по серым кнопочкам с заголовками полей). Нажатие на заголовок поля приводит к появлению фильтра по данным выбранной колонки/строки. Ниже приведен код на C# (перевод с Delphi сделал Shabal, за что ему большое спасибо):
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Text; using System.Windows.Forms; using System.Threading; using System.Globalization; using Excel = Microsoft.Office.Interop.Excel; namespace WinApp1 { public partial class Form1 : Form { public Form1() { InitializeComponent(); } private void button1_Click(object sender, EventArgs e) { const string cmdSelect = "select OrderDate, Year(OrderDate) as yy,\n" + "Month(OrderDate) as mm, Country, City, ProductName,\n" + "SalesPerson, Quantity, ExtendedPrice from Invoices"; Excel.PivotCache pivotCashe; Excel.PivotTable pivotTable; Excel.PivotField pivotField; Excel.Worksheet oSheet; Excel.Application xlApp = new Excel.Application(); string dataSource = Application.StartupPath + @"\..\..\Northwind.mdb"; button1.Enabled = false; label1.Visible = true; try { xlApp.Workbooks.Add(Type.Missing); xlApp.Visible = true; xlApp.Interactive = false; xlApp.EnableEvents = false; oSheet = (Excel.Worksheet)xlApp.ActiveSheet; oSheet.get_Range("A1", Type.Missing).Value2 = "Сводный отчет"; oSheet.get_Range("A1", Type.Missing).Font.Size = 12; oSheet.get_Range("A1", Type.Missing).Font.Bold = true; oSheet.get_Range("A1", Type.Missing).Font.Italic = true; oSheet.get_Range("A1", Type.Missing).Font.Underline = true; // создаем запрос pivotCashe = ((Excel.PivotCaches)xlApp.ActiveWorkbook.PivotCaches()). Add(Excel.XlPivotTableSourceType.xlExternal, Type.Missing); pivotCashe.Connection = string.Format("OLEDB;Provider=Microsoft.Jet.OLEDB.4.0;Data Source={0}", dataSource); pivotCashe.CommandType = Microsoft.Office.Interop.Excel.XlCmdType.xlCmdSql; pivotCashe.CommandText = cmdSelect; // создаем сводную таблицу на основе запроса (пока без полей) pivotTable = pivotCashe.CreatePivotTable(oSheet.get_Range("A3", Type.Missing), "MyPivotTable1", Type.Missing, Excel.XlPivotTableVersionList.xlPivotTableVersionCurrent); pivotTable.DisplayImmediateItems = false; pivotTable.EnableDrilldown = true; pivotTable.ManualUpdate = true; // настраиваем поля // поля колонок pivotField = (Excel.PivotField)pivotTable.PivotFields("yy"); pivotField.Orientation = Microsoft.Office.Interop.Excel.XlPivotFieldOrientation.xlColumnField; pivotField.Caption = "Год"; // сворачиваем данные по годам, чтобы влезли все данные for (int i = 1; i <= ((Excel.PivotItems)pivotField.PivotItems(Type.Missing)).Count; i++) { ((Excel.PivotItem)pivotField.PivotItems(i)).ShowDetail = false; } pivotField = (Excel.PivotField)pivotTable.PivotFields("mm"); pivotField.Orientation = Microsoft.Office.Interop.Excel.XlPivotFieldOrientation.xlColumnField; // сворачиваем данные по месяцам, чтобы влезли все данные for (int i = 1; i <= ((Excel.PivotItems)pivotField.PivotItems(Type.Missing)).Count; i++) { ((Excel.PivotItem)pivotField.PivotItems(i)).ShowDetail = false; } pivotField.Caption = "Месяц"; pivotField = (Excel.PivotField)pivotTable.PivotFields("OrderDate"); pivotField.Orientation = Microsoft.Office.Interop.Excel.XlPivotFieldOrientation.xlColumnField; pivotField.Caption = "Дата заказа"; // поля строк pivotField = (Excel.PivotField)pivotTable.PivotFields("SalesPerson"); pivotField.Orientation = Microsoft.Office.Interop.Excel.XlPivotFieldOrientation.xlRowField; pivotField.Caption = "Продавец"; pivotField = (Excel.PivotField)pivotTable.PivotFields("Country"); pivotField.Orientation = Microsoft.Office.Interop.Excel.XlPivotFieldOrientation.xlRowField; pivotField.Caption = "Страна"; pivotField = (Excel.PivotField)pivotTable.PivotFields("City"); pivotField.Orientation = Microsoft.Office.Interop.Excel.XlPivotFieldOrientation.xlRowField; pivotField.Caption = "Город"; pivotField = (Excel.PivotField)pivotTable.PivotFields("ProductName"); pivotField.Orientation = Microsoft.Office.Interop.Excel.XlPivotFieldOrientation.xlRowField; pivotField.Caption = "Изделие"; // // поля данных pivotField = pivotTable.AddDataField(pivotTable.PivotFields("Quantity"), "Кол-во", Microsoft.Office.Interop.Excel.XlConsolidationFunction.xlSum); //pivotField.Function = Microsoft.Office.Interop.Excel.XlConsolidationFunction.xlSum; // возможна персональная настройка формата вывода данных (не забываем о "культуре") // pivotField = pivotTable.AddDataField(pivotTable.PivotFields("ExtendedPrice"), "Сумма продаж", Microsoft.Office.Interop.Excel.XlConsolidationFunction.xlSum); // настроим "культуру" на англ., чтоб не зависить от локальных настроек int savedCult = Thread.CurrentThread.CurrentCulture.LCID; Thread.CurrentThread.CurrentCulture = new CultureInfo(0x0409, false); Thread.CurrentThread.CurrentUICulture = new CultureInfo(0x0409, false); try { // установим "американский" формат данных pivotField.NumberFormat = "#,##0.00"; // возможно задать формат сразу всей области даных! //pivotTable.DataBodyRange.NumberFormat = "#,##0.00"; } finally { // восстановим пользовательскую "культуру" для отображения всех данных в // привычных глазу форматах Thread.CurrentThread.CurrentCulture = new CultureInfo(savedCult, true); Thread.CurrentThread.CurrentUICulture = new CultureInfo(savedCult, true); } // убираем спиcок полей с экрана xlApp.ActiveWorkbook.ShowPivotTableFieldList = !(pivotTable.Version == Microsoft.Office.Interop.Excel.XlPivotTableVersionList.xlPivotTableVersion10); // рассчитаем таблицу pivotTable.ManualUpdate = false; xlApp.ActiveWorkbook.Saved = true; } finally { // отсоединяемся от Excel'я pivotField = null; pivotTable = null; pivotCashe = null; oSheet = null; xlApp.Interactive = true; xlApp.ScreenUpdating = true; xlApp.UserControl = true; xlApp = null; button1.Enabled = true; label1.Visible = false; } } private void Form1_FormClosing(object sender, FormClosingEventArgs e) { e.Cancel = !button1.Enabled; } } }Статья показывает лишь небольшие возможности Сводного отчета. Незатронутыми остались вопросы по созданию расчетных полей, сводных диаграмм и т.д.
Проект создавался и тестировался на Delphi 7, BDS 2006 и Excel2003. Исходные тексты программы на Delphi, база данных и пример отчета находятся в архиве PivotTable.zip. Исходные тексты на C# (VS2005) и база данных находятся в архиве WinApp1.zip. Более детальную информацию можно получить из файла vbaxl9.chm для Microsoft Excel 2000 или vbaxl10.chm для Microsoft Excel 2002, или с сайтов:
http://exceltip.com/excel_tips/Excel_Pivot_Tables/32.html http://msdn2.microsoft.com/ru-ru/library/microsoft.office.interop.excel.pivottable.aspx http://msdn2.microsoft.com/ru-ru/library/microsoft.office.interop.excel.pivotcache.aspx http://msdn2.microsoft.com/ru-ru/library/microsoft.office.interop.excel.pivotfields.aspxК материалу прилагаются файлы:Тестовый проект на Delphi (659 K)Тестовый проект на С# (500 K)
Реализация простейшего алгоритма распознавания графических образов.
Юрий Кисляков, Королевство Дельфи
На написание данного материала меня подвигла одна, нередко встречающаяся в ответах на вопросы круглого стола, фраза: "Если задумал написать свой … - даже не берись. Дело безнадежное. Это не для одиночек, и тем более не для начинающих (нужна команда серьезных математиков и программистов). Что касается различных "know how", то вряд ли владеющий ими поделится с кем-либо. Такая информация стоит бооольших денег..." На реализацию предлагаемого алгоритма у меня ушло примерно 15 часов.
Вашему вниманию предлагается программа распознавания рукописных прописных русских букв и цифр на основе метода сравнения с эталонными изображениями соответствующих символов.
Данный подход может быть использован для написания собственных модулей распознавания символов (в том числе рукописных) в разрабатываемом прикладном ПО.
Ниже приведены основные моменты реализации предлагаемого алгоритма.
Шаг 1. Создание канвы для рисования и формирование ее образа в памяти.
В качестве канвы используем класс TBitmap (для простоты работы с битмапом используем режим 1 байт на пиксель, т.е. TBitmap.PixelFormat := pf8bit), визуализируем его на TPaintBox, отображаем в памяти при помощи структуры: type MasX = PByteArray; var MasY : array of MasX // массив пикселей, { где MasY[y-коорд][x-коорд] = номер цвета в палитре цветов (при 8 бит/пиксель). Отображение осуществляем с использованием TBitmap.ScanLine (быстро и просто): SetLength(MasY, TBitmap.Height); for j := 0 to TBitmap.Height - 1 do MasY[j] := TBitmap.ScanLine[j]; } Теперь с картинкой в виде матрицы XxY можно делать все что угодно…
Шаг 2. Формирование массива эталонных образцов символов.
Эталонные образцы будем формировать на основе матрицы размером 16х16. Для этого разработаем процедуру генерации такой матрицы по произвольному изображению эталона.
Процедура function Create_16x16(Img : TBitmap) : TMas16x16 получает в качестве параметра ссылку на картинку, на которой нарисован эталон символа (в нашем случае - программно), возвращает приведенную матрицу размером 16х16.
Кратко поясним работу процедуры (более полно см. комментарии в программе).
Получаем ссылку на битмап и осуществляем его отображение в памяти (см. выше).
Вычисляем координаты границ (описанного прямоугольника) образа (эталонного или распознаваемого) путем сканирования строк/столбцов. При этом здесь и при дальнейшем анализе изображения предполагается, что символ нарисован черным цветом (№0 в палитре цветов) и соответственно все значащие пиксели имеют значение 0. for j := 0 to Img.Height - 1 do // Top begin for i := 0 to Img.Width - 1 do if MasY[j][i] = 0 then begin yTop := j; break; end; if yTop = j then break; end;
for j := Img.Height - 1 downto 0 do // Bottom begin for i := 0 to Img.Width - 1 do if MasY[j][i] = 0 then begin yBottom := j + 1; break; end; if yBottom = j + 1 then break; end;
for i := 0 to Img.Width - 1 do // Left begin for j := 0 to Img.Height - 1 do if MasY[j][i] = 0 then begin xLeft := i; break; end; if xLeft = i then break; end;
for i := Img.Width - 1 downto 0 do // Right begin for j := 0 to Img.Height - 1 do if MasY[j][i] = 0 then begin xRight := i + 1; break; end; if xRight = i + 1 then break; end;
Для дальнейшего анализа потребуется некий критерий, по которому будет производиться свертка исходного изображения символа в матрицу 16х16. Таким критерием был выбран общий процент заполнения - отношение количества значимых пикселей (из которых состоит символ) к общему количеству пикселей в описанном вокруг исходного изображения прямоугольнике. Данный параметр может влиять на качество распознавания, причем если он больше 1 для распознаваемого символа будет соответствовать меньшее количество возможных альтернатив, при значении меньшем 1 - наоборот. В нашем случае коэффициент поправки принят равным 0,99. nSymbol := 0; for j := yTop to yBottom do for i := xLeft to xRight do if MasY[j][i] = 0 then inc(nSymbol); Percent := nSymbol / ((yBottom - yTop)*(xRight - xLeft)); Percent := 0.99*Percent;
Далее разбиваем прямоугольник с изображением символа на 16х16 ячеек путем деления сторон новой ячейки на 2. Запоминаем относительные координаты кождой ячейки и приступаем к заполнению матрицы 16х16. Принимаем в качестве критерия общий процент заполнения. Если в анализируемой ячейке процент заполнения больше, чем общий процент - соответствующий элемент матрицы 16х16 устанавливается в 1, в противном случае - в 0.
Остальная часть алгоритма касается вопросов рисования на TBitmap букв или цифр (в цикле), запоминания в массиве матриц 16х16, соответствующих каждому эталонному символу (см. приведенный код).
Шаг 3. Распознавание рисованных (от руки) символов.
Распознавание осуществляем путем сравнения матрицы 16х16 распознаваемого символа с матрицей эталона (путем перебора имеющихся в наличии). Сравнение производим поэлементно при помощи оператора XOR. Результат - матрица 16х16, содержащая единицы в местах несовпадений тест-символа и эталона. Путем подсчета количества несовпадений формируем вектор, содержащий эту информацию для каждого эталонного символа, и производим сортировку эго элементов по возрастанию количества несовпадений.
Параметр (1 - Result[i]/256)*100%, где Result[i] - кол-во несовпадений для i - го символа, показывает "вероятность" соответствия образа конкретному символу.
Демонстрационная программа.
Пример работы демонстрационной программы Сгенерируйте массив шаблонов для букв или цифр, используя конкретный шрифт Нарисуйте от руки произвольную букву (русскую, прописную) или цифру Нажмите на кнопку анализ Исследуйте результат Очистите окно и повторите пп. 2-4.
Что дальше?
Данный алгоритм как простейший обладает рядом существенных ограничений.
Для повышения точности распознавания отдельных символов (не слов, - это другая задача, в каком-то смысле более простая), необходимо проводить дополнительный анализ значимых признаков, например симметричность образа (горизонтальная, вертикальная), наличие замкнутых областей (О, В, Д, Р и др.), количество отрезков и дуг, их взаимное расположение и ориентация (требуется векторизация изображения).
Буду рад, если этот материал кому-то пригодится.
К материалу прилагаются файлы: (5.8 K) обновление от 3/2/2006 6:15:00 AM
Немного математики
Разумеется, для простоты мы будем рассматривать только черно-белые изображения. Пусть у нас рисунок состоит всего из двух пикселей. Тогда множество всех объектов, которое можно будет изобразить (универсальное множество), состоит из четырех объектов: (0,0), (0,1), (1,0), (1,1), где 1 — черный пиксель, 0 — белый.
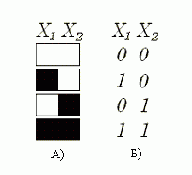
Рисунок 1
Все объекты универсального множества можно разместить в вершинах единичного квадрата, таким образом, множеству фигур, изображенных на двухпиксельном поле, может быть сопоставлено множество точек в двумерном пространстве. Ребру этого квадрата будет соответствовать переход от одного изображения к другому. Для перехода от (1,1) к (0,0) нужно будет пройти два ребра, для перехода от (0,1) к (0,0) — одно. Отметим, что число ребер в нашем переходе — это количество несовпадающих пикселей двух изображений. Вывод интересный: расстояние от одного рисунка до другого равно числу несовпадающих пикселей в них. Это расстояние называется расстоянием по Хэммингу.
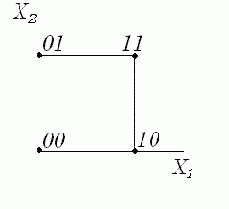
Рисунок 2
Теперь представим себе, что у нас рисунок состоит из трех пикселей. Коды изображений тогда будут состоять из трех значений, универсальное множество — из восьми элементов, которые мы разместим в вершинах единичного куба. Но принципиально ничего не изменится, и расстояние по Хэммингу вычисляется так же. В приложенной тестовой программе используется рисунок 50х70 = 3500 пикселей. Легко сообразить, что в этом случае код любого изображения состоит из 3500 значений, универсальное множество — из 23500 = 4,027 * 101053 элементов, которые мы будем размещать в вершинах единичного 3500-мерного куба. Представить себе такой 3500-мерный куб нелегко, но смысл от этого не меняется абсолютно. Основная идея заключается в том, что в этом многомерном кубе изображения, соответствующие какому-то определенному образу, лежат недалеко друг от друга. Эта идея получила название "Гипотеза о компактности образов".
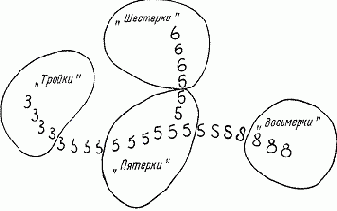
Рисунок 3
Теперь можно сформулировать задачу: нужно универсальное множество разбить на "куски", компактные множества, каждому из которых соответствует образ.
Программа
Итак, при запуске программы в массив Data: array of array [0..9] of TBitmap; записываются цифры от 0 до 9, написанные следующими шрифтами: Arial, Century Gothic, Courier New Cyr, Goudy Old Style и Times New Roman — всего пять комплектов (можно легко увеличить). Все эти изображения были сохранены мною и заботливо выложены в папку \fonts (более опытный программист, нежели я, наверняка сделал бы отрисовку, чтобы не мучаться с файлами).
| Procedure LoadData; var i,j:integer; path:string; begin SetLength(Data,5); for i := 0 to 4 do begin path := ExtractFilePath(Application.ExeName)+'\fonts\'; case i of 0: path := path + 'Arial\'; 1: path := path + 'Century Gothic\'; 2: path := path + 'Courier New Cyr\'; 3: path := path + 'Goudy Old Style\'; 4: path := path + 'Times New Roman\'; end; for j := 0 to 9 do begin Data[i,j] := TBitmap.Create; Data[i,j].LoadFromFile(path + IntToStr(j) + '.bmp'); end; end; end; |
После загрузки эталонных изображений пользователь рисует на поле размером 50х70 пикселей цифру, которую программа будет распознавать. При нажатии кнопки "распознать" высчитываются расстояния от распознаваемого рисунка до каждого из эталонных (расстояние по Хэммингу).
| function Compare( b1,b2:TBitmap):integer; var i,j,count:integer; begin count := 0; for i := 0 to 49 do for j := 0 to 69 do if b1.Canvas.Pixels[i,j] <> b2.Canvas.Pixels[i,j] then inc(count); Result := count; end; |
Зная это расстояние R, легко вычислить потенциал, создаваемый каждым эталонным рисунком в точке, соответствующей нарисованному пользователем изображению. Я немного изменил формулу расчета потенциала, чтобы избежать деления на 0 в случае R=0 и для лучшего восприятия домножил на 1 000 000:
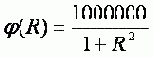
Рисунок 5
Потенциалы, создаваемые нулями всех начертаний, суммируются в p[0], единицами — в р[1] и так далее.
| for i := 0 to 4 do for j := 0 to 9 do begin r := Compare(Image1.Picture.Bitmap,Data[i,j]); p[j] := p[j] + 1000000/(1+r*r); end; |
После всего этого остается найти, какому образу соответствует наибольший потенциал.
Рисунок 6
Реализация
А собственно реализация проста до безобразия, если вы разобрались в математической части. Программе в процессе обучения сообщаются изображения (точки многомерного куба) и указания, к какому образу каждое изображение относится. При распознавании программа просто смотрит, в какую из известных компактных областей попало входное изображение. Скорее всего, все указанные машине изображения лягут более-менее компактно, поэтому универсальное множество будет можно разделить. Собственно разделять универсальное множество мы не будем, а будем пользоваться некоторой характеристикой, которая показывает удаленность одного рисунка (точки в вершине многомерного куба) до группы таких же изображений. В качестве меры удаленности рисунка от группы рисунков используется потенциал.
Известно, что электрический заряд создает вокруг себя поле, одной из характеристик которого является потенциал. В любой точке он может быть вычислен по формуле
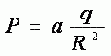
Рисунок 4
где a — некоторый постоянный коэффициент, q — величина заряда, R — расстояние от данной точки до заряда. Если электрическое поле образовано двумя или более зарядами, то потенциал в данной точке равен сумме потенциалов каждого заряда. Аналогия очевидна — каждый рисунок, на котором программа обучалась, создает в пространстве универсального множества потенциал. После обучения программе дают распознать какой-либо рисунок (точку в вершине многомерного куба), программа вычисляет потенциал, создаваемый в этой точке всеми объектами образа "а", образа "б"… на которых программу учили и распознаваемый рисунок относится к образу, который создал наибольший потенциал.
Вступление
На написание этого опуса меня спровоцировала статья Юрия Кислякова , который, по моему скромному мнению очень удачно начал мысль о том, что распознавание образов не есть что-то сверхсуперсложное, не поддающееся разуму простых смертных. Давным-давно уже во многих областях техники используются различные автоматы и устройства, более или менее удачно решающие задачу распознавания (это и автомат для сортировки почтовых конвертов по индексу, и зенитная ракета, захватывающая горячее сопло самолетного двигателя, но игнорирующая солнце, и различные системы анализа спутниковых снимков, и голосовой вызов вашего мобильника, и многое-многое другое), тем не менее, людей, уверенных в непреодолимой сложности алгоритмов, очень много. В статье Юрия, однако, есть одно сильное, на мой взгляд, упущение: его программу невозможно обучать, т.к. у него сравнение происходит только с одним набором эталонов. Предложу вашему вниманию алгоритм, который можно обучать. Особую пикантность алгоритму придает тот факт, что его математическое обоснование было предложено советскими математиками в начале 60х годов (т.е. в то время, когда компьютер не всегда помещался в среднестатистической квартире), а еще лет через 15 была доказана его весьма глубокая аналогия с очень популярным в настоящее время нейросетевым методом. Итак,
Предложенный метод дает весьма неплохие
Предложенный метод дает весьма неплохие результаты как на машинописных, так и на рукописных цифрах. Алгоритм легко может быть переобучен для различения других символов (латинских/русских букв, знаков препинания и т.п.). Для повышения надежности распознавания можно предусмотреть сильно различающиеся между собой эталоны (для того, чтобы как можно сильнее разбросать эталонные точки в пределах компактного множества). Для распознавания цифр я еще использовал такой прием: исходный рисунок разбивался на 7 участков по вертикали и 5 по горизонтали, участок целиком заливался белым либо черным в зависимости от того, каких пикселей участок содержал больше, после чего работа с каждым участком происходила как с пикселем. Очевидно, что после такого фокуса 99.9% восьмерок, написанных и от руки, и машинописных, будут иметь вид

Рисунок 7 после чего работать с таким изображением легко и приятно.
Буду очень рад, если моя статья кому-то будет полезна.
К материалу прилагаются файлы: (22 K) обновление от 1/17/2007 3:57:00 AM
ДОПОЛНЕНИЯ
В этой части собраны дополнения, которые не вошли в стандарт Borland. Эти дополнения взяты из правил JCL и опыта российских разработчиков.
Const, Var и Type
Зарезервированные слова var, const и type всегда пишутся на новой строке и не допускают появления на этой же строке какого-либо текста.
Правильно| type TMyType = Integer; const MyConstant = 100; var MyVar: Integer; |
| type TMyType = Integer; const MyConstant = 100; var MyVar: Integer; |
Процедуры должны иметь только по одной секции type, const и var в следующем порядке:
| procedure SomeProcedure; type TMyType = Integer; const ArraySize = 100; var MyArray: array [1..ArraySize] of TMyType; begin ... end; |
Директивы условной компиляции
Все директивы условной компиляции должны быть собраны в одном модуле ХХX.INC. Этот файл предназначен для определения глобальных директив. Оператор include должен быть помещен между ключевыми словами unit и interface. Никто не может мождифицировать файл ХХX.INC по собственному желанию.
Строковые ресурсы
Все строковые ресурсы должны иметь вид "Rs"[Category][Name]. [Category] должно быть аббревиатурой или названием категории кода, где используется строка. [Name] должно быть именем строки ресурса. Например, конструктор TJclCriticalSectionEx.CreateEx вызывает исключительную ситуацию при ошибке инициализации. Сообщение об ошибке объявляется в глобальном модуле ХХXResources.pas с именем RsynchInitCriticalSection.
Все строки должны быть исключены из кода и заменены на константы. Исключением из этого правила являются строки, которые являются какими-либо командами или от них будет зависеть поведение экземпляров класса. Такие строки должны быть явно объявлены в каком-либо из методов класса.
Исключения
Все исключения должны начинаться с префикса EХХХ. Все исключения должны быть отнаследованны от класса ENхError. При возбуждении исключительной ситуации предпочтительным является ее создание с помощью метода CreateRes:
| raise EХХХSomeException.CreateRes(@RsSomeResourceString); |
Категории и разделение алгоритмов
Обычно, содержимое каждого созданного модуля есть набор классов, функций и процедур, принадлежащих к одной категории. Например, ХХХLogin содержит все, что относится к идентификации и персонификации пользователя. Для ясного восприятия исходного кода следует придерживаться следующего правила: в интерфейсной части модуля каждая группа функций, относящихся к одной субкатегории должны отделяться от другой группы функций тремя строками шириной 80 столбцов с описанием субкатегории на второй строке:
| 1 2 Информация о последней попытке идентификации 3 procedure GetLastUserName(var ZUser: string); procedure GetLastDatabase(var ZDatabase: string); |
В секции реализации каждая подкатегория или класс должен разделяться строкой, состоящей из символов равенства (=), закомментированных однострочным комментарием и пустой строкой перед и после группы функций:
| //================================================= procedure GetLastUserName(var ZUser: string); begin ... end; procedure GetLastDatabase(var ZDatabase: string); begin ... end; //================================================== |
Каждая функция из одной группы или методы класса должны разделяться между собой строкой, состоящей из символов минуса (-), закомментированных однострочным комментарием и пустой строкой перед и после функции или метода:
| //================================================== procedure GetLastUserName(var ZUser: string); begin ... end; //-------------------------------------------------- procedure GetLastDatabase(var ZDatabase: string); begin ... end; //================================================== |
Ассемблер
Локальные процедуры
Локальные функции и процедуры должны иметь стандартный отступ в два пробела вправо от их владельца и сама процедура должна выделяться пустыми строками по одной перед и после локальной процедуры. Если "внешняя" процедура имеет локальные переменные, то они должны декларироваться перед локальной процедурой, независимо от того, будет ли в локальной процедуре осуществляться доступ к ним или нет. Однако общие соображения таковы, что локальных процедур следует избегать.
| procedure SomeProcedure; var I: Integer; procedure LocalProcedure; begin ... end; begin ... LocalProcedure; ... end; |
Объявление параметров
Когда объявляется список параметров для процедуры, функции или метода пользуйтесь следующими рекомендациями: Комбинируйте формальные параметры одного типа в одно выражение; Не используйте префикс А, кроме случаев, когда вызывается метод класса, который работает со свойством, которе имеет идентичное имя; Придерживайтесь следующего порядка в параметрах: сначала входные параметры, затем входные/выходные, затем выходные. Параметры, имеющие значение по умолчанию по правилам Object Pascal помещаются в конец списка; Используйте const для параметров, которые не изменяются при работе вызываемых методов, процедур или функций.Инициализация глобальных переменных
Глобальные переменные, как и члены класса всегда инициализируются нулем. Это трудно для понимания в случае разных типов. Например Integer инициализируется в 0, а pointer в nil. Для этого рекомендуется указывать в комментарии как инициализируется переменная.
| var MyGlobalVariable: Pointer // = nil; |
Несмотря на то, что глобальные переменные разрешены языком Object Pascal, используйте их лишь в самых крайних случаях.
ФАЙЛЫ ИСХОДНОГО КОДА
Исходный код Object Pascal подразделяется на модули и файлы проекта, которые подчиняются одинаковым соглашениям. Файл проекта Delphi имеет расширение DPR. Этот файл является главным исходным файлом для всего проекта. Любые модули, используемые в проекте, всегда будут иметь расширение PAS. Дополнительные файлы, используемые в проекте (командные, html, DLL и т.д.) могут играть важную роль, но эта глава описывает форматирование только PAS и DPR файлов.
Именование исходных файлов
Язык Object Pascal поддерживает длинные имена файлов. Если при создании имени Вы используете несколько слов, то необходимо использовать заглавную букву для каждого слова в имени: MyLongName.pas. Этот стиль оформления известен как InfixCaps или CamelCaps. Расширения файлов должны быть в нижнем регистре. Исторически, некоторые исходные файлы Delphi именуются по шаблону 8.3, но в настоящее время разработчики не обязаны придерживаться этого ограничения.
Если Вы осушествляете перевод заголовочных файлов C/C++, то паскалевский эквивалент должен иметь тоже самое имя и расширение PAS. Например Windows.pas. Если правила грамматики языка Object Pascal требуют объединения нескольких транслированных файлов в один, то используйте имя того файла, в который Вы вкладываете остальные. Например: если WinBase.h вкладывается в Windows.h, то результирующее имя будет Windows.pas.
Все файлы модулей, созданные в организации ХХХ должны иметь префикс ХХХОрганизация исходных файлов
Все модули Object Pascal могут содержать следующие элементы в определенном порядке: Информация о правах (Copyright/ID); Имя модуля (Unit Name); Объявление включаемых файлов (Include files); Секцию интерфейса (Interface section); Дополнительные определения (Additional defines); Объявление используемых модулей (Uses clause); Реализацию (Implementation) Объявление используемых модулей (Uses clause); Закрывающий оператор и точку (A closing end and a period). Для визуального разделения элементов между ними должна быть хотя бы одна пустая строка.Дополнительные элементы могут быть структурированы в порядке, который Вы сочтете нужным, но нужно соблюдать обязательные условия: в начале файла всегда копирайт, затем имя модуля, затем условные директивы и определения, директивы компилятора и файлы включения, затем определение подключений.
| {************************************************************} { } { Модуль ХХХ } { Copyright (c) 2001 ООО ХХХХ } { отдел/сектор } { } { Разработчик: ХХ ХХ } { Модифицирован: 25 июня 2001 } { } {************************************************************} unit Buttons; |
Директивы компилятора не следует напрямую включать в исходный код. Для этого следует воспользоваться определением включений и подключить глобальный для проекта файл с директивами компилятора:
| {$I NX.INC} interface |
В случае необходимости, можно напрямую переопределить глобальные директивы компилятора. Следует помнить, что переопределяющие директивы должны быть документированы и Вы должны постараться ограничиться только локальным переопределением. Например для одной процедуры:
| {$S-,W-,R-} {$C PRELOAD} interface uses Windows, Messages, Classes, Controls, Forms, Graphics, StdCtrls, ExtCtrls, CommCtrl; |
Секции определения типов и констант Вы можете располагать относительно друг друга как Вам угодно. Секция реализации должна начинаться с ключевого слова implementation, затем объявление используемых модулей (Uses clause), затем любые включение файлов или другие директивы.
| implementation uses Consts, SysUtils, ActnList, ImgList; {$R BUTTONS.RES} |
Копирайт и комментарий
Пример заголовка для модуля:| {************************************************************} { } { Модуль ХХХ } { Copyright (c) 2001 ООО ХХХХ } { отдел/сектор } { } { Разработчик: ХХ ХХ } { Модифицирован: 25 июня 2001 } { } {************************************************************} |
Объявление модуля
Каждый исходный файл должен содержать объявление модуля. Слово unit является ключевым, поэтому оно должно быть написано в нижнем регистре. Имя модуля может содержать символы как в верхнем, так и в нижнем регистре и должно быть таким же, как и имя используемое для этого файла операционной системой. Например:
unit MyUnit; Этот модуль будет назван MyUnit.pas, когда он будет сохранен операционной системойОбъявление используемых модулей
Внутри модуля объявление используемых модулей должно начинаться со слова uses в нижнем регистре. Затем следуют наименования модулей с сохранением регистра символов:
uses MyUnit;Каждый используемый модуль должен отделяться от следующего с помощью запятой. Объявление используемых модулей должно заканчиваться точкой с запятой. Список используемых модулей необходимо располагать на следующей строке после слова uses. Если используются модули из разных проектов или производителей, то необходимо сгруппировать модули по проектам или производителям и каждую новую группу начинать с новой строки и снабжать комментариями:
| uses Windows, SysUtils, Classes, Graphics, Controls, Forms, TypInfo // модули Delphi , XХХMyUnit1, ХХXMyUnit2; // модули ХХХ |
Объявление классов и интерфейсов
Объявление класса начинается с двух пробелов, затем идет идентификатор класса с префиксом Т в нотации InfixCaps. Ни в коем случае в исходных файлах Object Pascal нельзя использовать табуляцию:
TMyClass Следом за идентификатором класса идет пробел, знак равенства, пробел и слово class в нижнем регистре: TMyClass = class Если необходимо определить родителя класса, то следует добавить открывающую скобку, имя класса-родителя и закрывающую скобку: TMyClass = class(TObject)Объявления областей видимости начинаются с двух пробелов и, следовательно, области видимости распологаются на одном уровне с идентификатором класса:
| TMyClass = class(TObject) private protected public published end; |
Данные всегда должны располагаться только в приватной секции и названия переменных должны всегда начинаться с префикса F. Все объявления внутри класса должны начинаться с четырех пробелов:
| TMyClass = class(TObject) private FMyData: Integer; function GetData: Integer; procedure SetData(Value: Integer); public published property MyData: Integer read GetData write SetData; end; |
Оформление объявлений интерфейсов подчиняется тем же правилам, что и оформление классов. Отличие будет в использовании ключевых слов специфичных для интерфейсов
ИНТЕРФЕЙСЫ
Все основные правила форматирования для классов применяются и для форматирования интерфейсов. Интерфейсы декларируются в той же манере, что и классы.
| InterfaceName = interface([Inherited Interface]) InterfaceBody end; |
Отступ для интерфейса должен быть равен двум пробелам. Тело интерфейса имеет отступ четыре пробела. Закрывающий end должен иметь отступ в два пробела. Объявление класса заканчивается точкой с запятой. У интерфейса не существует полей, однако свойства могут присутствовать.
Все методы интерфейса являются абстрактными и общедоступными, поэтому не требуется включать слова public и abstract в объявление метода.
Структура тела интерфейса
Тело интерфейса при его декларации подчинено следующей структуре: Объявление методов интерфейса; Объявление свойств интерфейса. Стили для объявления свойств и методов интерфейса аналогичным стилям для класса.ИСПОЛЬЗОВАНИЕ ПРОБЕЛОВ
Использование пустых строк
Пустые строки могут повысить читабельность путем группирования секций кода, которые логически связаны между собой. Пустые строки должны использоваться в следующих местах:
После блока копирайта; После декларации пакета; После секции импорта; Между объявлениями классов; Между реализациями методов;Использование пробелов
Язык Object Pascal является очень легким для понимания языком, поэтому нет особой необходимости в использовании большого количества пробелов. Следующие пункты дадут Вам понимание того, в каком случае необходимо использовать пробелы.
Пробелы, запрещенные к использованию
До или после оператора .(точка); Между именем метода и открывающей скобкой; Между унарным оператором и его операндом; Между выражением приведения (cast) и приводимым выражением; После открывающей скобки или перед закрывающей; После открывающей квадратной скобки [ или перед закрывающей ]; Перед точкой с запятой; Примеры правильного использования: function TMyClass.MyFunc(var Value: Integer); MyPointer := @MyRecord; MyClass := TMyClass(MyPointer); MyInteger := MyIntegerArray[5]; Примеры неправильного использования: function TMyClass.MyFunc( var Value: Integer ) ; MyPointer := @ MyRecord; MyClass := TMyClass ( MyPointer ) ; MyInteger := MyIntegerArray [ 5 ] ;Использование отступов
Всегда необходимо использовать два пробела для всех уровней отступа. Другими словами, первый уровень отступает на два пробела, второй на четыре и так далее. Никогда не используйте символы табуляции.
Существует несколько исключений из этого правила. Зарезервированные слова unit, uses, type, interface, implementation, initialization и finalization всегда должны примыкать к левой границе. Также должны быть отформатированы финальный end и end, завершающий исходный модуль. В файле проекта выравнивание по левой границе применяется к словам program, главным begin и end. Код внутри блока begin..end должен иметь отступ два символа.
Перенос строк
Все строки должны быть ограничены 80 столбцами. Строки, длиннее чем 80 столбцов должны быть разделены и перенесены. Все перенесенные строки должны быть выровнены по первой строке и иметь отступ в два символа. Выражение begin всегда должно находиться на своей отдельной строке.
Пример:Правильно
| function CreateWindowEx(dwExStyle: DWORD; lpClassName: PChar; lpWindowName: PChar; dwStyle: DWORD; X, Y, nWidth, nHeight: Integer; hWndParent: HWND; hMenu: HMENU; hInstance: HINST; lpParam: Pointer): HWND; stdcall; |
Никогда не разрывайте строку между параметром и его типом, кроме параметров, перечисляемых через запятую. Двоеточие для всех объявлений переменных не должно содержать перед собой пробелов и иметь один пробел после перед именем типа.
Правильно procedure Foo(Param1: Integer; Param2: Integer); Неправильно procedure Foo( Param :Integer; Param2:Integer );Нельзя переносить строки в тех местах, где не допускаются пробелы, например между именем метода и открывающей скобкой или между именем массива и открывающей квадратной скобкой. Никогда нельзя помещать выражение begin на строку, содержащую другой код.
Неправильно| while (LongExpression1 or LongExpression2) do begin // DoSomething // DoSomethingElse; end; |
| if (LongExpression1) or (LongExpression2) or (LongExpression3) then |
КЛАССЫ
Структура тела класса
Тело класса при его декларации подчинено следующей структуре: Объявление полей; Объявление методов; Объявление свойств. Поля, свойства и методы в вашем классе должэны быть упорядочены в алфавитном порядке.Уровни доступа
Исключая код, вставленный IDE, директивы видимости должны быть объявлены в следующем порядке: Приватные (скрытые) члены класса (private); Защищенные члены класса (protected); Общедоступные члены класса (public); Публикуемые члены класса (published)Таким образом, в Object Pascal существует четыре уровня доступа для членов класса: published, public, protected и private - в порядке уменьшения видимости. По умолчанию, уровень доступа - published. В общем, члены класса должны давать наименьший уровень доступа, который подходит для этого члена. Например, член, к которому имеют доступ классы из одного модуля должен иметь уровень доступа private. Кроме того, объявляя члены класса с наименьшим уровнем доступа, Вы позволяете компилятору воспользоваться дополнительными возможностями для оптимизации. С другой стороны, если Вы планируете в дальнейшем порождать дочерние классы от Вашего класса, то нужно использовать уровень доступа protected.
Никогда не указывайте уровень доступа public для данных. Данные всегда должны быть объявлены в приватной секции и доступ к ним должен осуществляться с помощью методов или свойств.
Объявление конструктора
Все методы класса должны быть упорядочены по алфавиту. Однако Вы можете поместить объявления конструктора и деструктора перед всеми остальными методами. Если у класса существует более чем один конструктор и если они имеют одинаковые имена, то они должны располагаться в порядке увеличения числа параметровОбъявление методов
По возможности, объявление метода должно располагаться на одной строке:Например:
| procedure ImageUpdate(Image img, infoflags: Integer, x: Integer, y: Integer, w: Integer, h: Integer) |
Язык Object Pascal поддерживает два
Язык Object Pascal поддерживает два типа комментариев: блочные и однострочные. Общие соображение по использованию комментариев могут быть следующими:
Помещайте комментарий недалеко от начала модуля для пояснения его назначения; Помещайте комментарий перед объявлением класса; Помещайте комментарий перед объявлением метода; Избегайте очевидных комментариев: (i := i + 1 // добавить к i единицу); Помните, что вводящий в заблуждение комментарий хуже чем его отсутствие; Избегайте помещать в комментарий информацию, которая со временем может быть не верна; Избегайте разукрашивать комментарии звездочками или другими символами; Для временных (отсутствующие в релизе) комментариев используйте "TODO". Блочные комментарии
Object Pascal поддерживает два типа блочных комментариев. Наиболее часто используемый блочный комментарий - это пара фигурных скобок: { }. Команда разработчиков Delphi предпочитает использовать этот комментарий как можно проще и как запасной. Используйте в таких комментариях пробелы для форматирования текста и не используйте символы зведочка "*". При переносе строк необходимо сохранять отступы и выравнивание
Пример из DsgnIntf.pas:
| { TPropertyEditor Edits a property of a component, or list of components, selected into the Object Inspector. The property editor is created based on the type of the property being edited as determined by the types registered by... etc... GetXxxValue Gets the value of the first property in the Properties property. Calls the appropriate TProperty GetXxxValue method to retrieve the value. SetXxxValue Sets the value of all the properties in the Properties property. Calls the appropriate TProperty SetXxxxValue methods to set the value. } |
В блочный комментарий всегда заключается информация о модуле: копирайт, дата модификации и так далее. Блочный комментарий, описывающий метод должен идти перед объявлением метода.
Правильно
| { TMyObject.MyMethod This routine allows you to execute code. } procedure TMyObject.MyMethod; begin end; |
Неправильно
| procedure TMyObject.MyMethod; {****************************************************** TMyObject.MyMethod This routine allows you to execute code. *******************************************************} begin end; |
Второй тип блочного комментария содержит два символа: скобку и звездочку: (* *). Этот тип комментария используется при разработке исходного кода. Его преимуществом является то, что он поддерживает вложенные комментарии, правда комментарии должны быть разного типа. Вы можете использовать это свойство для комментирования больших кусков кода, в котором встречаются другие комментарии:
| (* procedure TForm1.Button1Click(Sender: TObject); begin DoThis; // Start the process DoThat; // Continue iteration { We need a way to report errors here, perhaps using a try finally block ??? } CallMoreCode; // Finalize the process end; *) |
Однострочные комментарии
Однострочный комментарий состоит из символов // со следующим за ними текстом комментария. После символов // должен идти пробел и затем текст. Однострочные комментарии должны иметь отступы такие же, как и код, в котором они встречаются. Однострочные комментарии можно сгруппировать, чтобы сформировать большой комментарий.
Однострочный комментарий может начинаться с новой строки и может продолжать код, который он комментирует. В этом случае между кодом и комментарием должен быть хотя бы один пробел. Если больше одного комментария следует за кодом, то они должны быть выровнены по одному столбцу.
Пример однострочного строкового комментария:
| // Open the table Table1.Open; |
Пример комментария в коде:
| if (not IsVisible) then Exit; // nothing to do Inc(StrLength); // reserve space for null terminator |
Необходимо избегать использовать комментарии в коде для каждой строки модуля.
ОПЕРАТОРЫ
Операторы - это одна или более строк кода, разделенных точкой с запятой. Простые операторы имеют одну точку с запятой, а составные могут иметь более чем одну точку с запятой и, таким образом, состоят из множества простых операторов.
Это простой оператор: A := B; Это составной или структурированный оператор: begin B := C; A := B; end;Простые операторы
Простые операторы содержат одну точку с запятой. Если Вам необходимо разделить операторы, то перенесите продолжение оператора на следующую строку с отступом в два пробела:
MyValue := MyValue + (SomeVeryLongStatement / OtherLongStatement);Составные операторы
Составные операторы всегда заканчиваются точкой с запятой. begin MyStatement; MyNext Statement; MyLastStatement; end;Присвоения и выражения
Каждое присвоение и каждое выражение должно располагаться на разных строках.Правильно a := b + c; Inc(Count); Неправильно a := b + c; Inc(Count);
Объявление локальных переменных
Локальные переменные должны иметь стиль Camel Caps. Для локальных переменных префикс F не требуется. var MyData: Integer; MyString: string; Все переменные с их типами, особенно поля класса, должны быть объявлены на различных строках.Объявление массивов
В объявлении массива перед и после квадратных скобок должны стоять пробелы. type TMyArray = array [0..100] of Char;Оператор if
Оператор if всегда должен располагаться по крайней мере на двух строкахНеправильно if A < B then DoSomething; Правильно if A < B then DoSomething;
В случае составного оператора необходимо поместить каждый оператор на новую строку.
Неправильно| if A < B then begin DoSomething; DoSomethingElse; end else begin DoThis; DoThat; end; |
| if A < B then begin DoSomething; DoSomethingElse; end else begin DoThis; DoThat; end; |
Все остальные варианты расположения операторов не рекомендуются и не одобряются, хотя и являются синтаксически правильными. Избегайте использования круглых скобок в простых проверках. Например:
Правильно if I > 0 then DoSomething; Неправильно if (I > 0) then DoSomething;Оператор for
Неправильно| for i := 0 to 10 do begin DoSomething; DoSomethingElse; end; |
| for i := 0 to 10 do begin DoSomething; DoSomethingElse; end; for I := 0 to 10 do DoSomething; |
Оператор while
Неправильно| while x < j do begin DoSomething; DoSomethingElse; end; |
| while x < j do begin DoSomething; DoSomethingElse; end; while x < j do Something; |
Оператор repeat until
Правильно| repeat x := j; j := UpdateValue; until j > 25; |
Оператор case
Несмотря на то, что существует множество синтаксически правильных конструкций, одобренной и рекомендованной считается следующая:
Правильно| case ScrollCode of SB_LINEUP, SB_LINEDOWN: begin Incr := FIncrement div FLineDiv; FinalIncr := FIncrement mod FLineDiv; Count := FLineDiv; end; SB_PAGEUP, SB_PAGEDOWN: begin Incr := FPageIncrement; FinalIncr := Incr mod FPageDiv; Incr := Incr div FPageDiv; Count := FPageDiv; end; else Count := 0; Incr := 0; FinalIncr := 0; end; |
Оператор try
Несмотря на то, что существует множество синтаксически правильных конструкций, одобренной и рекомендованной считается следующая:
Правильно| try try EnumThreadWindows(CurrentThreadID, @Disable, 0); Result := TaskWindowList; except EnableTaskWindows(TaskWindowList); raise; end; finally TaskWindowList := SaveWindowList; TaskActiveWindow := SaveActiveWindow; end; |
СОГЛАШЕНИЕ ОБ ИМЕНОВАНИЯХ
Исключая зарезервированные слова и директивы, которые всегда пишутся в нижнем регистре, все идентификаторы Object Pascal должны использовать InfixCaps:
MyIdentifier MyFTPClassСамое главное исключение для всех правил состоит в использовании оттранслированных заголовочных файлов С/С++. В этом случае всегда используются соглашения, принятые в файле источнике. Например будет использоваться WM_LBUTTONDOWN, а не wm_LButtonDown.
Для разделения слов нельзя использовать символ подчеркивания. Имя класса должно быть именем существительным или фразой с именем существительным. Имена интерфейсов или классов должны отражать главную цель их создания:
Правильно: AddressForm ArrayIndexOutOfBoundsException Неправильно: ManageLayout (глагол) delphi_is_new_to_me (подчерк)Именование модулей
Смотрите пункт 2.1.Именование классов и интерфейсов
Смотри объявление классов и интерфейсов.Именование полей
При именовании полей всегда необходимо использовать InfixCaps. Всегда объявлять переменные только в приватных частях и использователь свойства для доступа к переменным. Для переменных использовать префикс F.
Имена процедур для установки/получения значений свойств должны составляться по правилу: для получения - Get+имя свойства; для установки - Set+имя свойства.
Не используйте все заглавные буквы для констант, за исключением оттранслированных заголовочных файлов. Не используйте Венгерскую нотацию, за исключением оттранслированных заголовочных файлов. Правильно FMyString: string; Неправильно lpstrMyString: string; Исключение для Венгерской нотации делается в случае объявления перечислимого типа: TBitBtnKind = (bkCustom, bkOK, bkCancel, bkHelp, bkYes, bkNo, bkClose, bkAbort, bkRetry, bkIgnore, bkAll); bk обозначает ButtonKindКогда Вы раздумываете над именами переменных, то имейте в виду, что нужно избегать однобуквенных имен, кроме как для временных переменных и переменных цикла.
Переменные цикла именуются I и J. Другие случаи использования однобуквенных переменных это S (строка) и R (результат). Однобуквенные имена должны всегда использовать символ в верхнем регистре, но лучше использовать боле значимые имена. Не рекомендуется использовать переменную l (эль), потому что она похожа на 1 (единица).
Именование методов
При именовании полей всегда необходимо использовать стиль InfixCaps. Не допускается использование символов подчеркивания для разделения слов. В имени метода всегда должна содержаться команда к действию или глагольная фраза
Правильно: ShowStatus DrawCircle AddLayoutComponent Неправильно: MouseButton (Существительное, не описывает функцию) drawCircle (Начинается с маленькой буквы) add_layout_component (Используются символы подчерка) ServerRunning (Глагольная фраза, но без команды)Обратите внимание на последний пример (ServerRunning) - непонятно, что делает этот метод. Этот метод может использоваться для запуска сервера (лучше StartServer) или для проверки работы сервера (лучше IsServerRunning).
Методы для установки или получения значений свойств должны именоваться Get+имя свойства и - Set+имя свойства.
Например:
GetHeight, SetHeigh
Методы для теста/проверки булевских свойств класса должны именоваться с префиксом Is+имя свойства.
Например:
IsResizable, IsVisible
Именование локальных переменных
Имена всех локальных переменных должны подчиняться тем же правилам, которые установлены для именования полей, исключая префикс F.
Зарезервированные слова
Зарезервированные слова и директивы должны быть все в нижнем регистре. Производные типы должны начинаться с большой буквы (Integer), однако string - это зарезервированное слово и оно должно быть в нижнем регистре.
Объявление типов
Все объявления типов должны начинаться с префикса Т и должны придерживаться правил, приведенных при описании оформления модуля или описании оформления класса.
Этот стандарт документирует стилевое оформление
Этот стандарт документирует стилевое оформление для форматирования исходного кода Delphi. Оригинал статьи создан Чарльзом Калвертом и расположен на . В стандарте использованы материалы команды разработчиков Delphi, сообщества разработчиков библиотеки JEDI. Стандарт так же дополнен некоторыми правилами, созданными на основе собственного опыта разработки.
Object Pascal является замечательно спроектированным языком. Одним из его многочисленных достоинств является легкая читабельность. Предлагаемый стандарт позволит еще более повысить легкость чтения кода Object Pascal. Следование довольно простым соглашениям, приведенным в этом стандарте, позволит разработчикам понять, что унифицированное оформление намного повышает читабельность и понятность кода. Использование стандарта намного облегчит жизнь во время этапов разработки и тестирования, когда довольно часто приходится подменять друг друга и разбираться в чужом коде.
Процесс перехода с собственного стиля оформления на предлагаемый может оказаться непростым, но человеческий мозг довольно легко адаптируется к стандартам и находит пути для быстрого запоминания предлагаемых правил. В дальнейшем, следование стандарту не вызывает затруднений. Для более комфортабельного перехода на этот стандарт предагается воспользоваться свободно распространяемой утилитой для форматирования исходных текстов .
Хочется отметить, что в компании Borland, на Web-сайте компании Borland, на CD, купленных у компании Borland, везде где есть исходный код, стандарт форматирования является законом.
Этот документ не является попыткой определить грамматику языка Object Pascal. Например, если Вы попытаетесь поставить точку с запятой перед выражением else, то компилятор не позволит Вам этгого сделать. Этот документ говорит Вам, как нужно поступать, когда есть возможность выбора из многих вариантов при оформлении Вашего исходного кода.
Дальнейшие планы
Дальнейших планов много.
Расширить количество и качество примеров пакета. Создать нормальную документацию. "Научить" генераторы создавать тестовые *.dpr файлы для быстрой проверки анализаторов. Создать *.hrc-файл для для подсветки синтаксиса в .L и .Y файлах. Переписать код чтения символов из потока OLex для увеличения производительности (существующий код работает, но не очень эффективно). Портировать код под FreePascal (а там и под Linux).Автор с благодарностью примет всякие нарекания, пожелания и сообщения об ошибках.
Выражаю благодарность Шилову Сергею за комментарии к статье.
Скачать архив: (183 K)
и синтаксических анализаторов теперь станет
Давно назревавшие изменения наконец-то были сделаны.
Изготовление лексических и синтаксических анализаторов теперь станет (на взгляд автора) несколько более удобным. Возможно, это изменит ситуацию, когда бытует мнение, что "компиляторы пишут только на C!" и можно будет теперь делать это на Delphi.
Автору будет очень приятно знать, что его работа кому-то оказалась полезной.
Изменение TP Lex & Yacc
Дмитрий Соломенников,
Статья предполагает знакомство читателей с основами лексического и синтаксического анализа, пакетом TP Lex&Yacc, и, разумеется, Delphi.
Работая над несколькими проектами в Delphi, автору пришлось сделать немало лексических и синтаксических анализаторов с помощью пакета TP Lex/Yacc. Оставив за рамками статьи обсуждение вопроса "Почему это не сделать на C (C++)?", попробую показать проблемы, с которыми пришлось столкнулся и решение, которое позволило мне преодолеть большую часть из них. Сразу скажу, что я описываю готовое решение, которое работает в нескольких проектах. Название ему - OLex и OYacc. Название дано по аналогии с реализацией пакета TP Lex&Yacc для Linux под Free Pascal. Там программы называются plex и pyacc соответственно. Приставка "O" означает объекты.
Новые директивы OLex и OYacc
Ниже приведен список директив, реализующих нововведения.
Директивы OLex
%scannername <имя>
Директива задает имя сканера. Имя <имя> будет вставлено везде, где появляется название сканера; название сканера будет T<имя>Scanner. Например, если указать в коде .L файла %scannername Advanced, то любое упоминание названия сканера будет выглядеть как TAdvancedScanner.
%useslist <список имен>
Директива задает список используемых сканером библиотек. <список имен> представляет собой список идентификаторов через пробел. Например, если указать в коде .L файла %useslist LexLib Unit1 Unit2, то в результирующем файле появится строка uses LexLib, Unit1, Unit2;. Директива рассчитана на то, что хотя бы одна библиотека (OLexLib) в этом списке будет, а потому она обязательно должна присутствовать в .L файле.
Директивы OYacc
%parsername <имя>
Директива задает имя парсера. Имя <name> будет вставлено везде, где появляется название парсера; название парсера будет T<имя>Parser. Например, если указать в коде .Y файла %parsername Advanced, то любое упоминание названия парсера будет выглядеть как TAdvancedParser.
%scannername
Директива задает название сканера, сгенерированного программой OLex. В результирующем файле создается инфраструктура использования сгенерированного сканера и указывается его имя. Формат такой же, как и у директивы %scannername в OLex.
%noscanner
Предполагается, что парсер использует поток токенов, поступающих от сканера. Сканер может генерироваться программой OLex, а может быть написан разработчиком транслятора. И в том, и в другом случае обращение парсера за следующим токеном происходит посредством обращения к свойству yylex сгенерированного класса. То, в свою очередь, вызывает метод чтения Getyylex. Директива %noscanner определяет, как реализуется метод Getyylex. В случае, если директива в .Y файле отсутствует, то будет использоваться метод, который обращается ко встроенному сканеру (сгенерированному OLex-ом); в противном случае разработчик должен сам объявить и реализовать метод. Делается это посредством включения нижеуказанного кода в .Y файл:
function T@@ParserName@@Parser.Getyylex: Integer;
begin
<Здесь должен быть код лексического анализатора>;
end;
Код этот должен располагаться после второго разделителя %%. Назначение символов @@ раскрывается ниже.
%tokenfile <имя>
Если в исходном .Y файле определены токены через директиву %token, то в генерируемый файл добавляются конструкции вида const token_name=<число>. Кроме того, если у токенов определить тип, то кроме списка токенов в генерируемый файл вставляется также и определение типа YYSType. И то, и другое требуется знать лексическому анализатору, чтобы выдавать и токен, и его значение (посредством поля yylval). Однако, возникла циклическая зависимость модулей сканера и парсера. Обоим надо иметь определения констант и типа YYSType; созданием же этой информации занимается генератор парсера. Поэтому было принято решение о выносе констант и определения файлов в отдельный файл. Имя этого файла и задает директива %tokenfile. Если директиву не задать, то будет сгенерирован файл tokens.pas, иначе будет сформирован файл с названием <имя>.pas. Файл токенов строится на основе нового файла-шаблона yyotoken.cod.
%useslist <список имен>
Директива имеет тот же смысл, что и в .L файле.
Подстановки второго этапа
Новые директивы относятся к первому этапу обработки входного файла. Второй этап состоит в том, что генератор раскрывает подстановки вида @@<текст>@@. Здесь <текст> зависит от генератора.
Подстановки Lex
@@UNITNAME@@
Имя сгенерированного файла без расширения. Используется для записи имени модуля и берется из имени .L файла.
@@SCANNERNAME@@
Название сканера, задаваемое директивой %scannername. Заменяется на , указываемое после директивы.
@@USESLIST@@
Список библиотек, используемых сканером. Представляет собой строку вида "name1, name 2, name3". Здесь name1, name2, name3 - элементы списка "%useslist name1 name2 name3".
@@DATE@@
Текущая дата. Полезно для установки даты создания файла в шапке.
Подстановки Yacc
@@UNITNAME@@
Имя сгенерированного файла без расширения. Используется для записи имени модуля и берется из имени .Y файла.
@@PARSERNAME@@
Название парсера, задаваемое директивой %parsername. Заменяется на <имя>, указываемое после директивы.
@@SCANNERNAME@@
Название сканера, задаваемое директивой %scannername. Заменяется на , указываемое после директивы.
@@USESLIST@@
Список библиотек, используемых парсером. Представляет собой строку вида "name1, name 2, name3" Здесь name1, name2, name3 - элементы списка "%useslist name1 name2 name3".
@@USESCANNERDEFINE@@ Заменяется на строку "{$DEFINE UseOLexScanner}", если директива %noscanner НЕ задана и на строку "{.$.DEFINE UseOLexScanner}", если директива %noscanner задана.
@@DATE@@
Текущая дата. Полезно для установки даты создания файла в шапке.
История
Занимаясь разработкой трансляторов на Delphi, рано или поздно сталкиваешься с пакетом TP Lex and Yacc (автор Albert Graef). Пакет этот максимально повторяет оригинальные Lex и Yacc, генерирующие код на языке C. Этот факт при переходе на язык Pascal порождает ряд проблем, а точнее неудобств, которые связаны с различиями в трансляции и структуре языков C и Pascal. Оригинальный Yacc, равно как и TP Yacc, генерируют выходной файл, содержащий функцию yyparse. Тоже самое делает и Lex. И если в языке C полученный файл является самодостаточной синтаксической единицей, то в Pascal этот файл еще надо как-то "прикрутить" к проекту. Вариантов сделать это не так много. В Pascal объявление функции должно находиться в том же синтаксическом модуле, что и ее реализация, поэтому сгенерированный файл либо сам должен быть модулем, либо должен включаться в уже заготовленный модуль директивой {$I }.
В первом случае .y файл выглядит примерно так:
%{
unit <имя файла>;
interface
uses
<список модулей>;
function yyparse: Integer;
implementation
%}
<Определения>
%%
<Продукции>
%%
end.
Во втором случае надо уже два (как минимум) файла:
файл модуля <parser.pas>
unit <имя файла>;
interface
uses
<список модулей>;
function yyparse: Integer;
implementation
{$I <parser_y.pas>}
end.
и файл parser_y.y (этот файл нельзя называть parser.y, что было бы вполне логичным, из-за конфликта имен).
Оставив в стороне споры о том, на каком языке делать генераторы и тот факт, что в C включение файлов является встроенной возможностью, рассмотрим более внимательно то, что имеем.
В первом случае имеет место заметное замусоривание исходного файла анализатора, которое увеличивает сложность и без того непростого модуля транслятора. Во втором случае сильно усложняется отладка и сопровождение проекта (за счет увеличения количества файлов). В Pascal не очень приветствуются включаемые файлы - механизм их использования и отладки довольно слабый.
Проблемы
С этими сложностями можно было бы мириться, если бы не два НО.
1) Генерируемые анализаторы слабо вписываются в объектную модель Delphi.
Генератор создает функцию, которая в своей работе использует дополнительный модуль (LexLib и YaccLib для лексического и синтаксического анализаторов соответственно). Встраивание анализатора-функции в проект, собранный сплошь из объектов, является весьма нетривиальной проектной задачей.
Кроме того, лексический анализатор использует консоль и текстовые файлы как источник символов. Это и медленно, и неудобно, учитывая, что сама среда Delphi и создаваемые ей программы используют механизм потоков .
Alexey Mahotkin в свое время предпринял попытку реализовать механизм потоков в Lex. Однако, на мой взгляд, этого недостаточно. Неудобства, описанные выше, все равно остаются.
2) Очень сложно сделать несколько анализаторов в одном проекте.
Использование общего кода из подключаемых модулей для нескольких анализаторов делает одновременное использование анализаторов очень проблематичным. Использовать-то их можно, но только попеременно, иначе будут нарушены все структуры, опираясь на которые ведется анализ (массивы состояний, хотя бы).Работа с OLex и OYacc
Изменения коснулись и работы с кодом, включаемом в .L и .Y файлы. Ранее в исходном файле до первого разделителя %% можно было указывать директивы, определения и включаемый код (код вставлялся между скобок %{ %}). Теперь, в связи с тем, что генерируется класс, надо включать не исполняемый код, а некоторые определения, вставляемые в класс сканера (парсера) в раздел public.
После второго разделителя можно было включать исполняемый код уже безо всяких скобок. И сейчас можно вставлять без скобок, однако, учитывая, что создается класс, код должен писаться, учитывая этот факт. В качестве примера можно посмотреть на реализацию калькулятора expr из примеров TP Lex & Yacc посредством OYacc (см. папку example)
expr.y:
...
%{
x : array [1..26] ofReal;
procedure Execute;
%}
%useslist OYaccLib ExprLex Tokens
...
%%
...
%%
procedure T@@ParserName@@Parser.Execute;
var
i : Integer;
begin
for i := 1 to 26 do x[i] := 0.0;
if yyparse=0 then { done };
end;
Код для процедуры Execute полностью копируется в генерируемый файл, и на втором этапе работы @@ParserName@@ будет заменено названием, заданным директивой %parsername (или удалено, если директива не указана).
Список подключаемых модулей должен включать модуль Tokens или модуль, определенный директивой %tokenfile последним для того, чтобы была определен тип YYSType. Delphi берет определения из того модуля, который указан в uses последним.
Кроме того, в генерирумых файлах создаются функции, которые позволяют создать экземпляры анализаторов. Для лексического анализатора функция имеет название New@@ScannerName@@Scanner, для синтаксического анализатора - New@@ParserName@@Parser.
Функция New@@ScannerName@@Scanner получает на вход три параметра: указатели входной и выходной потоки и Boolean параметр _UseConsole. Третий параметр имеет значение по умолчанию False, так что на входе используются потоки. Иначе - потоки игнорируются и на входе используется консоль (процедура Readln).
Функция New@@ParserName@@Parser имеет два варианта - с параметрами или без. Какой вариант будет рабочим, определяет директива %noscanner. Если директива не указана, то функция имеет такие же параметры, как и New@@ScannerName@@Scanner (при создании парсера создается экземпляр сканера, название которого задается директивой %scannername в .Y файле, и конструктору сканера передаются параметры функции). Если же директива %noscanner указана, то парсер использует реализацию сканера, предоставленную разработчиком, а потому никаких параметров конструктору не передается.
Как и у анализаторов в TP Lex & Yacc, у анализаторов OLex и OYacc наблюдается странная особенность - они в упор отказываются работать, если не установлены опции компилятора Range checking и Overflow checking.
Работа по созданию "внутренностей" транслятора не отличается от работы с TP Lex & Yacc - можно обратиться к документации пакета для дальнейшего изучения.
Проанализировав все имеющиеся реализованные автором
Проанализировав все имеющиеся реализованные автором анализаторы, были сделаны следующие наблюдения:
модуль (unit) создается всегда; включаемые файлы не используются; для каждого анализатора создается класс-обертка или вызывающий метод класса; некоторые анализаторы используют консоль для ввода символов, некоторые - потоки, некоторые файлы типа Text; разные анализаторы используют один и тот же разделяемый код из библиотек LexLib и YaccLib. Обобщение наблюдений привело к тому, что было решено произвести переделку генераторов таким образом, чтобы они генерировали модули, содержащий классы, соответствующие лексическому и синтаксическому анализаторам.
Реализация задачи потребовала довольно значительных изменений в исходных кодах пакета.
Встраивание в механизм работы генераторов автору показалось весьма сложным, поэтому было принято решение вносить изменения, опираясь на существующий механизм работы.
Были произведены следующие изменения.
Для того, чтобы отличать оригинальные библиотеки от измененных, имена файлов были изменены:
БылоСтало
| LexLib.pas | OLexLib.pas |
| YaccLib.pas | OYaccLib.pas |
| yylex.cod | yyolex.cod |
| yyparse.cod | yyoparse.cod |
Работа с генерируемым файлом была поделена на два этапа. Первый - это "честная" работа Lex (Yacc) по созданию генератора. Учитывая структуру шаблона, генераторы создают метод класса, yylex или yyparse, в зависимости от анализатора. Второй этап - это работа непосредственно с созданным файлом по его доводке. В шаблон встроены некоторые подстановочные символы, которые заменяются названием модуля, класса и т.д. (полный перечень приведен ниже). Для поддержки второго этапа были введены соответствующие изменения в генераторы.
Выбор источника символов был ограничен консолью и входящим потоком. Сделано это было из соображений практичности - работу с текстовыми файлами удобно проводить и с помощью потоков, а консоль иногда все-таки нужна для коротких фильтров. Собственно выбор осуществляется при помощи параметра _useconsole конструктора класса TBaseScanner.
Фиксированное дерево
Для того чтобы устранить недостатки простого дерева, нужно иметь указатель не только на непосредственного предка, но и на всех остальных предков выше по иерархии. Если максимальная глубина дерева ограничена, то это можно сделать в той же самой таблице путем введения дополнительных полей-ссылок. Если еще добавить поле для хранения уровня узла (что поможет в реализации операций с деревом), то получим следующую структуру (в данном случае максимальная глубина дерева равна 5):
Таблица MainTable
| ID | Autoincrement | Первичный ключ |
| Lev | Integer | Уровень текущего узла |
| Parent1 | Integer | Ссылка на родителя 1-го уровня (корень) |
| Parent2 | Integer | Ссылка на родителя 2-го уровня |
| Parent3 | Integer | Ссылка на родителя 3-го уровня |
| Parent4 | Integer | Ссылка на родителя 4-го уровня |
| Parent5 | Integer | Ссылка на родителя 5-го уровня |
| Name | Char | Название узла |
Поле Lev может принимать значения от 1 (корень дерева) до 5 (узел максимально возможной глубины). Значение поля ParentN для любого N равно: значению первичного ключа предка уровня N (при N < Lev); значению первичного ключа текущего узла (при N = Lev); 0 (при N > Lev). {GetLevel -- вспомогательная функция, которая возвращает уровень узла Node. Выделена для упрощения реализации основных процедур.} function GetLevel(Node : Integer) : Integer; begin with OpenQuery(Format('SELECT Lev FROM MainTable WHERE ID='+IntToStr(Node))) do Result:=Fields[0].AsInteger; end; procedure OutTree(Root : Integer); var S : String; Q : TQuery; L : Integer; begin L:=GetLevel(Root); S:='SELECT * FROM MainTable WHERE Parent%d=%d '+ 'ORDER BY Parent1,Parent2,Parent3,Parent4,Parent5'; Q:=OpenQuery(Format(S,[L,Root])); while NOT Q.Eof do begin OutNode(Q.FieldByName('ID').AsInteger, Q.FieldByName('Lev').AsInteger-L, Q.FieldByName('Name').AsString); Q.Next; end; end; procedure AddNode(Parent : Integer; const Name : String); var S : String; L : Integer; begin L:=GetLevel(Parent); if L >= 5 then Exit; // Следующий запрос не будет работать в Local SQL. S:='INSERT INTO MainTable (Lev,Parent1,Parent2,Parent3,Parent4,Parent5,Name) '+ 'SELECT Lev+1,Parent1,Parent2,Parent3,Parent4,Parent5,"%s" FROM MainTable '+; 'WHERE ID=%d'; ExecQuery(Format(S,[Name,Parent])); S:='UPDATE MainTable SET Parent%d=ID WHERE ID=%d'; ExecQuery(Format(S,[L+1,LastInsertID])); end; procedure DeleteNode(Node : Integer); var S : String; begin S:='DELETE FROM MainTable WHERE Parent%d=%d'; ExecQuery(Format(S,[GetLevel(Node),Node])); end; function NodeInSubtree(Node,Parent : Integer) : Boolean; var S : String; Q : TQuery; begin S:='SELECT Parent%d FROM MainTable WHERE ID=%d'; Q:=OpenQuery(Format(S,[GetLevel(Parent),Node])); Result:=(Q.Fields[0].AsInteger = Parent); end; procedure SetParent(Node,Parent : Integer); var S : String; Q : TQuery; NodeL,ParentL,dL,i : Integer; function DecLevel : String; var j : Integer; begin Result:=''; for j:=NodeL to 5 do Result:=Result+Format('Parent%d=Parent%d,',[j-dL,j]); for j:=5-dL+1 to 5 do Result:=Result+Format('Parent%d=0,',[j]); Result:=Result+Format('Lev=Lev-%d,',[dL]); end; function IncLevel : String; var DelS : String; j : Integer; begin Result:=''; DelS:='DELETE FROM MainTable WHERE (Parent%d=%d) AND (Lev>%d)'; ExecQuery(Format(DelS,[NodeL,Node,5+dL])); for j:=5 downto (NodeL-dL) do Result:=Result+Format('Parent%d=Parent%d,',[j,j+dL]); Result:=Result+Format('Lev=Lev+%d,',[-dL]); end; begin NodeL:=GetLevel(Node); Q:=OpenQuery(Format('SELECT * FROM MainTable WHERE ID=%d',[Parent])); ParentL:=Q.FieldByName('Lev').AsInteger; dL:=NodeL-ParentL-1; S:='UPDATE MainTable SET '; if dL <> 0 then begin if dL > 0 then S:=S+DecLevel else S:=S+IncLevel; end; for i:=1 to ParentL do S:=S+Format('Parent%d=%d,',[i,Q.Fields[i+1].AsInteger]); S[Length(S)]:=#32; ExecQuery(Format(S+'WHERE Parent%d=%d',[NodeL,Node])); end;
Как видно из приведенных примеров, в реализации всех операций удалось уйти от рекурсии. Количество запросов не зависит ни от количества узлов в дереве, ни от его глубины. Да и сама реализация стала несколько проще за исключением процедуры SetParent. На самом деле в ней не так все страшно, как кажется. Просто я попытался в одну процедуру запихнуть обработку нескольких различных ситуаций, которые, по уму, должны обрабатываться самостоятельно. На всякий случай (если кому-то сложно разбирать мои паскалевские каракули) хочу привести примеры запросов, которые реализуют эту операцию для различных ситуаций (запросы не сработают на Local SQL).
Ситуация 1. При изменении родителя происходит уменьшение уровня узла. Пусть мы узлу Node уровня 3 назначаем родителем узел Parent уровня 1. В результате выполнения операции уровень всех узлов поддерева Node уменьшится на 1. UPDATE MainTable AS T1,MainTable AS T2 SET T1.Lev=T1.Lev-1,T1.Parent1=T2.Parent1,T1.Parent2=T1.Parent3, T1.Parent3=T1.Parent4,T1.Parent4=T1.Parent5,T1.Parent5=0 WHERE (T1.Parent3=Node) AND (T2.ID=Parent);
Ситуация 2. При изменении родителя происходит увеличение уровня узла. Пусть мы узлу Node уровня 2 назначаем родителем узел Parent уровня 2. В результате выполнения операции уровень всех узлов поддерева Node увеличится на 1. Если в поддереве узла Node имеются узлы уровня 5, то они должны быть предварительно удалены, так как выйдут за пределы допустимой глубины дерева. DELETE FROM MainTable WHERE (Parent2=Node) AND (Lev>=5); UPDATE MainTable AS T1,MainTable AS T2 SET T1.Parent5=T1.Parent4,T1.Parent4=T1.Parent3,T1.Parent3=T1.Parent2, T1.Parent2=T2.Parent2,T1.Parent1=T2.Parent1,T1.Lev=T1.Lev+1 WHERE (T1.Parent2=Node) AND (T2.ID=Parent);
Ситуация 3. При изменении родителя не происходит изменение уровня узла. Пусть мы узлу Node уровня 3 назначаем родителем узел Parent уровня 2. В результате выполнения операции уровень всех узлов поддерева Node не меняется. UPDATE MainTable AS T1,MainTable AS T2 SET T1.Parent1=T2.Parent1,T1.Parent2=T2.Parent2 WHERE (T1.Parent2=Node) AND (T2.ID=Parent);
Кстати, фиксированное дерево -- единственный вариант представления дерева, для которого мне удалось в полном объеме решить вставшую изначально проблему: вывести все узлы поддерева в нужном порядке одним запросом.
К материалу прилагаются файлы:
(342 K) обновление от 5/4/2006 5:24:00 AM (9 K) обновление от 5/4/2006 5:24:00 AM
Неограниченное дерево
Фиксированное дерево очень удобно в работе. Но что делать, если по условию задачи невозможно ограничить максимальную глубину дерева? В этом случае придется задавать отношения между узлами более привычным способом. Родительские и дочерние узлы находятся в отношении many-to-many (каждому родительскому узлу может соответствовать множество дочерних, а каждому дочернему -- множество родительских, начиная с непосредственного предка и кончая корнем всего дерева). В соответствии с теорией, такое отношение реализуется вводом дополнительной таблицы.
Таблица MainTable
| ID | Autoincrement | Первичный ключ |
| Name | Char | Название узла |
Таблица LinkTable
| ParentID | Integer | Ссылка на родительский узел |
| ChildID | Integer | Ссылка на дочерний узел |
| Distance | Integer | Расстояние между узлами |
Значение поля Distance равно 0, если ParentID и ChildID совпадают. В противном случае оно равно порядковому номеру узла ChildID при движении к нему по дереву от узла ParentID. procedure OutTree(Root : Integer); var L : Integer; procedure MakeLevel(ParentID : Integer; const ParentName : String); var S : String; Q : TQuery; begin OutNode(ParentID,L,ParentName); Inc(L); S:='SELECT ID,Name FROM MainTable AS M JOIN LinkTable AS L ON (M.ID=L.ChildID) '+ 'WHERE (L.ParentID=%d) AND (L.Distance=1) ORDER BY ID'; Q:=OpenQuery(Format(S,[ParentID])); while NOT Q.Eof do begin MakeLevel(Q.FieldByName('ID').AsInteger,Q.FieldByName('Name').AsString); Q.Next; end; Dec(L); end; begin L:=0; with OpenQuery('SELECT Name FROM MainTable WHERE ID='+IntToStr(Root)) do MakeLevel(Root,FieldByName('Name').AsString); end; procedure AddNode(Parent : Integer; const Name : String); var S : String; NewNode : Integer; begin ExecQuery(Format('INSERT INTO MainTable (Name) VALUES ("%s")',[Name])); NewNode:=LastInsertID; // Следующий запрос не будет работать в Local SQL. S:='INSERT INTO LinkTable (ParentID,ChildID,Distance) '+ 'SELECT ParentID,%d,Distance FROM LinkTable '+ 'WHERE ChildID=%d'; ExecQuery(Format(S,[NewNode,Parent])); S:='INSERT INTO LinkTable (ParentID,ChildID,Distance) VALUES (%d,%0:d,0)'; ExecQuery(Format(S,[NewNode])); end; procedure DeleteNode(Node : Integer); var S : String; begin S:='DELETE FROM MainTable '+ 'WHERE ID IN (SELECT ChildID FROM LinkTable WHERE ParentID=%d)'; ExecQuery(Format(S,[Node])); S:='DELETE FROM LinkTable '+ 'WHERE ChildID IN (SELECT ChildID FROM LinkTable WHERE ParentID=%d)'; ExecQuery(Format(S,[Node])); end; function NodeInSubtree(Node,Parent : Integer) : Boolean; var S : String; Q : TQuery; begin S:='SELECT Count(*) FROM LinkTable WHERE (ParentID=%d) AND (ChildID=%d)'; Q:=OpenQuery(Format(S,[Parent,Node])); Result:=(Q.Fields[0].AsInteger > 0); end; procedure SetParent(Node,Parent : Integer); var S : String; Parents,Subtree : String; begin Parents:=Format('SELECT ParentID FROM LinkTable '+ 'WHERE (ChildID=%d) AND (ParentID<>%0:d)',[Node]); Subtree:=Format('SELECT ChildID FROM LinkTable '+ 'WHERE ParentID=%d',[Node]); S:='DELETE FROM LinkTable '+ 'WHERE (ParentID IN ('+Parents+')) AND (ChildID IN ('+Subtree+'))'; ExecQuery(S); // Следующий запрос не будет работать в Local SQL. S:='INSERT INTO LinkTable (ParentID,ChildID,Distance) '+ 'SELECT T1.ParentID,T2.ChildID,T1.Distance+T2.Distance+1 '+ 'FROM LinkTable AS T1,LinkTable AS T2 '+ 'WHERE (T1.ChildID=%d) AND (T2.ParentID=%d)'; ExecQuery(Format(S,[Parent,Node])); end;
Как нетрудно заметить, для неограниченного дерева хорошо реализуются все операции за исключением вывода поддерева: получить одним запросом все узлы, входящие в поддерево, достаточно легко, но вот упорядочить их так, чтобы получилось дерево, мне не удалось. Если кто знает способ, как можно представить неограниченное дерево в БД, чтобы любое поддерево можно было вывести одним запросом с учетом правильного порядка, то мне это по-прежнему очень интересно.
Ответы на предполагаемые часто задаваемые вопросы
1. Я скопировал кусок кода из статьи к себе в программу, после чего... (компилятор выдал ошибку, запрос не выполняется, компьютер виснет).
Не копируйте код из статьи. Если хочется что-нибудь скопировать, то скачайте исходники демонстрационной программы и копируйте оттуда ;-)
2. Я решил поискать в интернете дополнительные материалы по этой теме. Нашел немного про фиксированное дерево, но там совсем про другое. А про простое и неограниченное дерево я вообще ничего не нашел.
Тысяча извинений. Термины Простое Дерево, Фиксированное Дерево и Неограниченное Дерево не являются общеупотребительными. Я их придумал для данной статьи, чтобы как-то называть различные варианты представления деревьев, которые я рассматриваю.
3. Не кажется ли Вам, что использование других вариантов представления (отличных от простого дерева) -- это избыточные затраты дискового пространства?
Нет, не кажется. Если Вы взялись за базы данных, то Вы заведомо приняли решение пожертвовать эффективностью использования дискового пространства ради повышения быстродействия обработки больших объемов данных. Например, в демонстрационной программе я отвел под название узла 40 символов, хотя при тестировании не использовал названий длиннее 10 символов. Итого, таблица на 75% состоит из "воздуха". Если Вас заботит дисковое пространство, то вместо баз данных используйте, например, формат Tab Delimited Text и будет Вам счастье ;-)
4. Приведенные структуры ... (недостаточны, неоптимальны). Будет лучше сделать...
Делайте ;-)
5. Почему Вы не используете параметры в запросах? Ведь это более правильно.
Есть два варианта ответа: короткий и длинный. Короткий: мне показалось, что так будет нагляднее. Длинный приводить не буду, чтобы не раздувать размер статьи.
6. Зачем вообще нужны эти хитрые структуры, ведь сервер СУБД оптимизирует выполнение хранимых процедур?
Если сервер СУБД действительно умеет оптимизировать хранимые процедуры, в которых выполняются рекурсивные вызовы запросов, то данная статья представляет исключительно академический интерес.
7. Вывод всего дерева целиком в реальных задачах не требуется.
Если этот так, то значит Вы и я всего лишь напрасно потратили время ;-)
И еще несколько слов, если можно. В процессе работы над статьей, я решил поискать по Королевству другие материалы аналогичной тематики. Статей похожих мне не попалось (может быть, плохо искал?), а вот на Круглом Столе я обнаружил ответы Елены Филипповой на один из вопросов (). Приятно видеть, что два умных человека могут независимо прийти к одним и тем же выводам ;-) Кстати, одну небольшую идейку я у Елены украл (так как ее вариант показался мне более интересным) в чем готов принародно покаяться.
Специально для
Постановка задачи
В этой статье я рассматриваю несколько различных вариантов представления деревьев в базах данных, то есть структуры таблиц и реализацию некоторых операций по работе с деревьями через SQL-запросы к этим таблицам. Подчеркиваю, что речь идет о структуре данных и об операциях обработки. Вопросы написания компонент для представления деревьев здесь не рассматриваются.
Сразу уточню кое-какие моменты: эта статья написана для показа идеи, но не реализации. Отсюда несколько следствий. Я по возможности старался использовать максимально простые запросы, ориентируясь на Local SQL. Это сделано специально, чтобы идея была понятна как можно большему числу читателей. Если начать использовать более оптимальные конструкции, характерные для какой-либо продвинутой СУБД, это может привести к сложностям понимания для людей, работающих с другой СУБД. По той же причине вся программная обработка запросов в примерах написана на Delphi (то есть на стороне клиента), хотя на практике это лучше реализовать на сервере через хранимые процедуры и триггеры. Также в некоторых местах я, возможно, упускаю особенности обработки данных в некоторых экстремальных условиях (добавление первой записи в пустую таблицу, удаление последней записи из таблицы). Просто чтобы не загромождать код примера обработкой различных вариантов, которые усложнят понимание той самой идеи.
В принципе, Паскаль достаточно прост и понятен. И его вполне можно использовать для описания алгоритмов. Но, чтобы еще лучше сконцентрироваться на главном, я при описании реализации операций исхожу из предположения, что у меня имеется несколько вспомогательных функций, реализация которых в рамках данной статьи не существенна. Для простоты понимания тех, кто привык к правильному коду, можно считать, что у меня имеется дополнительный модуль, в котором определены некоторые специальные функции: unit SpecialFunctions; interface uses DBTables; {Процедура выводит узел с идентификатором ID, текстом Name и уровнем номер Level} procedure OutNode(ID,Level : Integer; const Name : String); {Функция создает запрос с текстом, переданным через StrSQL, открывает и возвращает его. Подразумевается запрос SELECT} function OpenQuery(const StrSQL : String) : TQuery; {Процедура выполняет запросы UPDATE, INSERT и DELETE, текст которых передан через StrSQL} procedure ExecQuery(const StrSQL : String); {Функция возвращает идентификатор последней записи, добавленной через запрос INSERT} function LastInsertID : Integer;
Используя процедуру OutNode, мы последовательно выводим узлы дерева. Как и куда будут выводиться эти узлы, не важно. Параметр Level определяет уровень узла (для древовидного отображения). Предполагается также, что запросы, полученные от функции OpenQuery, автоматически уничтожаются, после использования. Чтобы не загромождать код вызовом метода Free, обработкой исключений и прочими деталями, не представляющими сейчас интереса.
В статье рассматриваются три варианта представления деревьев. Для каждого из них приведены реализации пяти операций, которые показались мне наиболее необходимыми. Вот эти операции: {Процедура выводит поддерево, начиная с узла Root (нижнее замыкание). Для вывода используется вспомогательная процедура OutNode. Как и куда осуществляется вывод, не важно) procedure OutTree(Root : Integer); {Процедура добавляет узел с названием Name, делая его потомком узла Parent.} procedure AddNode(Parent : Integer; const Name : String); {Процедура удаляет поддерево, начиная с узла Node} procedure DeleteNode(Node : Integer); {Функция возвращает true, если узел Node находится в поддереве узла Parent. Данная функция необходима для проверки того, можно ли изменить структуру дерева и сделать узел Parent потомком узла Node. Если проверку не проводить, то возможно появление циклов, которые в дереве недопустимы.} function NodeInSubtree(Node,Parent : Integer) : Boolean; {Процедура изменяет структуру дерева, назначая узел Parent родителем узла Node.} procedure SetParent(Node,Parent : Integer);
Пример реализации
В свое время у нас в институте ходила такая шутка, что "на экзамене по общей физике ответ со взрывом -- лучше, чем ответ без взрыва". Подразумевалось, что, если ответ сопровождается экспериментом, то больше шансов получить хорошую оценку. В соответствии с этим нехитрым правилом я решил написать к данной статье небольшую демонстрационную программу, хотя никакая программа изначально не подразумевалась, так как статья чисто теоретическая.
Программа достаточно проста. В выпадающем списке выбираем тип дерева и по данным из БД соответствующее дерево строится на главной панели (слегка модифицированный ListBox). Операции по изменению дерева выполняются из контекстного меню. Обращаю внимание, что команды относятся к текущему узлу дерева (выделенному цветом), а не к тому, над которым произведен клик мышью. Если текущего узла нет, то операции невозможны. Операция изменения родителя вызывается методом Drag and Drop (берем мышью узел и перетаскиваем его на нового родителя). Для вывода поддерева, начиная с некоторого узла, можно выполнить Double Click на этом узле. Обратного перехода (или возможности подняться выше по дереву) нет. Чтобы от поддерева вернуться к полному дереву, нужно снова выбрать дерево того же типа из выпадающего списка типов.
Все три дерева хранятся в БД на Paradox 7. Это было сделано, чтобы обеспечить максимальную совместимость с программным обеспечением всех желающих попробовать программу: не уверен, что у каждого жителя Королевства имеется на компьютере Oracle или MS SQL, но уж BDE наверняка проинсталлировали все. Для работы программы файлы БД должны находится в директории DATA, которая, в свою очередь, должна находится там же, где и исполняемый файл (DBTree.exe). База данных уже частично заполнена. Все необходимый файлы содержатся в том же архиве, что и исходники программы. На случай, если у кого-то возникнут проблемы с компиляцией (а побаловаться с программой захочется), в отдельном архиве выкладываю скомпилированный EXE-файл.
И еще, программа является довеском к статье, но никак не предметом рассмотрения. Отсюда несколько следствий. Во-первых, хотя я и старался писать код поаккуратнее, но вот комментариями, мягко выражаясь, не злоупотреблял. Так что возможны трудности при разборках с исходниками. Во-вторых, это все же не законченный программный продукт, ориентированный на конечного пользователя, а маленькая демонстрашка. Так что в ней не реализована в полной мере противодураковая защита. Заранее известные глюки: не проверяется длинна строки для имени узла (максимальное значение не должно быть более 40 символов), под первичный ключ отводится всего 16 бит (если попытаться создавать более 32767 узлов, то возникнут глюки), под последним добавленным узлом понимается узел с максимальным значением первичного ключа (возможны сбои при работе в многопользовательском режиме). Так что погонять дерево туда-сюда можно, но серьезно насиловать программу не стоит. Она для этого не предназначена.
Простое дерево
Наиболее простой и распространенный способ представления деревьев в базах данных состоит из одной таблицы примерно следующей структуры:
Таблица MainTable
| ID | Autoincrement | Первичный ключ |
| ParentID | Integer | Ссылка на родительский узел |
| Name | Char | Название узла |
Подобный подход очень прост, однако не позволяет сразу выделить все поддерево, начиная с заданного узла. Для работы с поддеревом требуется рекурсивная обработка данных. procedure OutTree(Root : Integer); var L : Integer; procedure MakeLevel(ParentID : Integer; const ParentName : String); var S : String; Q : TQuery; begin OutNode(ParentID,L,ParentName); Inc(L); S:='SELECT ID,Name FROM MainTable WHERE ParentID=%d ORDER BY ID'; Q:=OpenQuery(Format(S,[ParentID])); while NOT Q.Eof do begin MakeLevel(Q.FieldByName('ID').AsInteger,Q.FieldByName('Name').AsString); Q.Next; end; Dec(L); end; begin L:=0; with OpenQuery('SELECT Name FROM MainTable WHERE ID='+IntToStr(Root)) do MakeLevel(Root,FieldByName('Name').AsString); end; procedure AddNode(Parent : Integer; const Name : String); var S : String; begin S:='INSERT INTO MainTable (ParentID,Name) VALUES (%d,"%s")'; ExecQuery(Format(S,[Parent,Name])); end; procedure DeleteNode(Node : Integer); procedure DeleteLevel(Parent : Integer); var S : String; Q : TQuery; begin S:='SELECT ID FROM MainTable WHERE ParentID=%d'; Q:=OpenQuery(Format(S,[Parent])); while NOT Q.Eof do begin DeleteLevel(Q.FieldByName('ID').AsInteger); Q.Next; end; S:='DELETE FROM MainTable WHERE ID=%d'; ExecQuery(Format(S,[Parent])); end; begin DeleteLevel(Node); end; function NodeInSubtree(Node,Parent : Integer) : Boolean; var S : String; Q : TQuery; begin Result:=false; while Node <> Parent do begin S:='SELECT ParentID FROM MainTable WHERE ID=%d'; Q:=OpenQuery(Format(S,[Node])); Node:=Q.FieldByName('ParentID').AsInteger; if Node = 0 then Exit; end; Result:=true; end; procedure SetParent(Node,Parent : Integer); var S : String; begin S:='UPDATE MainTable SET ParentID=%d WHERE ID=%d'; ExecQuery(Format(S,[Parent,Node])); end;
При такой организации дерева, только добавление нового узла и назначение узлу нового родителя (то есть операции, для выполнения которых знание структуры дерева не требуется) реализуются достаточно эффективно. А вывод дерева и удаление поддерева требуют рекурсивной обработки. Проверка вхождения узла в поддерево хотя и реализуется без рекурсии, однако количество вызовов запросов также зависит от структуры дерева (от глубины, если быть точнее), что не является эффективным. Надо попробовать другие варианты представления дерева.
Сравнительный анализ
Проведем небольшой сравнительный анализ различных вариантов представления дерева с точки зрения качества реализации рассмотренных в статье операций. Будем считать, что операция реализуется хорошо, если количество запросов для реализации не зависит от характеристик дерева (количества узлов, глубины и др.). Если же зависимость есть, то будем считать, что операция реализуется плохо.
| Простое | Фиксированное | Неограниченное | ||
| 1 | Вывод дерева | плохо | хорошо | плохо |
| 2 | Добавление узла | хорошо | хорошо | хорошо |
| 3 | Удаление узла | плохо | хорошо | хорошо |
| 4 | Вхождение узла в поддерево | плохо | хорошо | хорошо |
| 5 | Изменение родителя | хорошо | хорошо | хорошо |
Из таблицы видно, что простое дерево слабо годится для работы с ним на уровне БД. Только две операции из пяти будут выполняться эффективно. Но так как для изменения родителя нужно сначала определить, допустимо ли такое изменение, а операция проверки вхождения узла в поддерево также реализуется плохо, то остается одно лишь добавление нового узла. Для задачи, в которой в основном выполняется только операция добавления нового узла, а остальные операции выполняются крайне редко, такой вариант подойдет. Но я как-то слабо могу себе представить такую задачу (ведение древовидных логов что ли?). Так что применять простое дерево имеет смысл для сравнительно небольших деревьев, которые выгружаются из БД в какие-либо компоненты (например, TTreeView), а вся дальнейшая работа производится уже на уровне компонентов.
Для фиксированного дерева все операции реализуются хорошо. Так что, если по условиям задачи допустимо ограничить максимальную глубину дерева, то, возможно, это будет лучший вариант (если не будет придуман способ хорошей реализации вывода неограниченного дерева). Имейте в виду, что максимальную глубину для фиксированного дерева можно задать и побольше, чем 5. Можно взять с запасом. Главное -- чтобы глубину можно было хоть как-то ограничить.
Ну, а если таких ограничений задать невозможно (или если скорость вывода не критична), то можно воспользоваться вариантом неограниченного дерева.
Увидеть за лесом деревья
,
Сидел я как-то раз на одном форуме, на котором темы отображались в виде полностью раскрытого дерева. И залезла мне в голову шальная мысль: а как можно сделать такой вот древовидный форум, чтобы данные хранились в БД, а список тем выдавался одним запросом. Причем, чтобы порядок записей тоже определялся в этом запросе, а не приходилось потом полученные темы отсортировывать руками. Попробовал решить задачу "кавалерийским наскоком". Не получилось. Наиболее простая структура, задающая дерево, требовала рекурсивного вызова запросов, а мне это не понравилось. Придумать же более сложную структуру, которая позволяла бы построить дерево с учетом моих требований, долго не получалось.
Так как задача не была критичной, то я не просиживал ночи напролет, пытаясь ее решить, а просто возвращался к ней время от времени, когда хотелось поразмять мозги. И, в конце концов, что-то напридумывал. Этими придумками я и хочу поделиться.
На кого рассчитана данная статья? В основном, на программистов, которые более-менее знакомы с реляционными базами данных и языком SQL (плюс некоторое знакомство с Delphi), и которые имеют желание совершенствоваться в разработке баз данных. Начинающим, пожалуй, будет тяжеловато, так как я не опускаюсь до деталей. А вот профессионалы, возможно, найдут для себя кое-что интересное.
