
Многораздельное масштабирование TPC-C
Чтобы проанализировать влияние многораздельных транзакций на более сложную рабочую нагрузку, мы увеличивали долю транзакций TPC-C, затрагивающих несколько разделов. Мы выполняли рабочую нагрузку, на 100% состоящую из новых транзакций заказа с 6 складами. Затем мы соответствующим образом подбирали вероятность того, что некоторая позиция заказа поступает из "удаленного" склада, в результате чего получалась многораздельная транзакция. При параметрах TPC-C, используемых по умолчанию, эта вероятность составляет 0,01 (1%), что обеспечивает долю многораздельных транзакций, равную 9,5%. Мы изменяли этот параметр и вычисляли вероятность того, что транзакция является многораздельной. Пропускная способность системы при этой рабочей нагрузке показана на рис. 9.
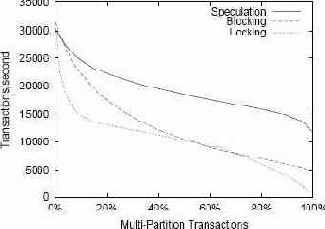
Рис. 9. 100% новых транзакций заказа из TPC-C
Результаты системы с блокировочной и спекулятивной схемами очень похожи на результаты микротестирования с рис. 4. В этом эксперименте производительность системы со схемой синронизационных блокировок очень быстро деградирует. При отсутствии многораздельных транзакций (0%) такая система работает эффективно без запросов блокировок. Но при появлении многораздельных транзакций блокировки должны запрашиваться. Накладные расходы на синхронизационные блокировки в тестовом наборе TPC-C выше, чем при микротекстировании, по трем причинам: больше блокировок запрашивается в каждой транзакции; более сложен сам менеджер блокировок; имеется большее число конфликтов. В частности, в этой рабочей нагрузке проявляются локальные и распределенные синхронизационные тупики, причиняющие существенный ущерб производительности. Это еще раз показывает, что конфликты делают традиционное управление параллелизмом более дорогостоящим, возрастают преимущества более простых схем.
Анализ результатов выборочного профилировщика при пропуске системы со схемой синхронизационных блокировок на TPC-C с вероятностью многораздельных транзакций, равной 10%, показывает, что 34% времени выполнения тратится на поддержку блокировок. Примерно 12% времени тратится на управление таблицы блокировок, 14% – на запросы блокировок, и 6% – на освобождение блокировок. Хотя в нашей реализации имеется простор для оптимизаций, эти цифры схожи с теми, которые были получены для Store, где на работу с синхронизационными блокировками тратилось до 16% команд процессора [14].
