
А теперь поразмыслим:
Главный вывод, который можно сделать, ознакомившись с принципами функционирования DDR II и RDRAM, заключается в том, что индустрии придется совершить нелегкий выбор. Ведь если для RDRAM повышение скорости работы интерфейса пропорционально росту его пропускной способности, то для DDR II данный показатель очень быстро выходит в "насыщение". Как следствие, даже DDR первого поколения для определенного рода приложений может оказаться более привлекательным решением, чем DDR II. Как уже отмечалось, временные характеристики DDR II по сравнению с DDR SDRAM сильно ухудшились, а 8 тактов до первого доступа к данным, и минимум 3 для осуществления записи, вообще отпугивают, равно как и низкая эффективность обработки команд "произвольного" чтения. (Вряд ли схема отложенного CAS даст сильный прирост производительности.) Произвольная выборка весьма характерна для серверных систем и научных компьютеров, следовательно, именно в этой сфере переход на DDR II может затянуться больше всего. С другой стороны, высокопроизводительные системы и по сей день остаются очень привлекательной позицией для нанесения "контрудара" Rambus.
Что касается общих слабых сторон новых технологий, к ним стоит отнести в первую очередь не самое эффективное использование каналов. Так, в случае с DDR II контроллер, которому потребуется считать объем информации размером, скажем, 1 бит, будет вынужден "тянуть" все-таки целых 4 бита (4-bit Prefetch), что связано с особенностями кэширования. Тоже самое с RDRAM. Здесь царит, с одной стороны, "избыток" управляющей информации, а с другой - низкая эффективность опроса и постановки задач, как следствие борьбы с большим количеством избыточных данных. Резонный баланс в этом вопросе "нащупать" достаточно сложно.
В итоге однозначного ответа об эффективности какого-либо из стандартов, по крайней мере, на данном этапе их развития дать нельзя. Поэтому судьбу стандартов предопределит рыночная конъюнктура. Сегодня она уверенно склоняет чашу весов в сторону DDR II.
К этому "приложила руку" компания Intel, а также лидеры рынка графических акселераторов, уже неоднократно испробовавшие новую память в своих флагманских решениях. Впрочем, и RDRAM все же еще присутствует на рынке ПК. Ее лагерь составляют ASUS, SiS и Rambus, которые заявляют о своих планах по разработке 4-канального чипсета на базе PC1200 DRDRAM для Pentium 4 с шиной 800 МГц QP. Все же их усилия кажутся тщетными, ведь сегодня именно производители процессоров задают тон в выборе "широт" пропускных каналов шин процессоров. А они в последние время стали весьма требовательными к этому показателю, ведь максимальная полоса пропускания процессорной шины того же Pentium 4 составляет 6,4 Гбайт/с. Современные же типы памяти в одноканальном режиме способны организовать канал шириной лишь 3,2 Гбайт/с у DDR-памяти, и 4,8 Гбайт/с - у RDRAM. Следует также учесть, что в дальнейшем этот разрыв станет увеличиваться, и, пожалуй, наступит момент, когда многоканальностью контроллера памяти проблемы "нестыковки" шин будет уже не решить, из-за сильного удорожания наборов системной логики. Как следствие, приоритеты ведущих игроков могут кардинально измениться.
DDR II - по накатанной дорожке
Уже из названия (DDR II) прослеживается близкая родственная связь этого типа памяти с SDRAM и DDR SDRAM первого поколения. Впрочем, DDR II - это не просто увеличенные частоты функционирования, усовершенствованная логика контроллера и сниженное энергопотребление, это еще и новая архитектура, которая имеет ряд фундаментальных отличий. Наиболее важное и значимое нововведение DDR II - использование 4-битной упреждающей выборки (4-bit Prefetch), позволяющей по сравнению с частотой синхронизации увеличить скорость ввода/вывода данных в четыре раза. Напомним, память DDR позволяла получить лишь двукратное увеличение данного показателя. При этом частота тактовых импульсов по сравнению с наиболее продвинутыми реализациями SDRAM и DDR изменилась не существенно - в настоящее время ведущие производители памяти выпускают модули DDR II с эффективными частотами, не превышающими 533 МГц. Поэтому по скорости синхронизации память DDR II в настоящее время самой продвинутой не назовешь, да и высокая эффективная частота функционирования вовсе не означает более интенсивной работы.
Высокая скорость ввода/вывода у DDR II достигается, как и у DDR, передачей двух блоков данных в пределах одного такта, что в совокупности с удвоенной частотой буферов ввода/вывода дает учетверенный показатель эффективной частоты. Внутренняя же частота ядра у DDR II 400 МГц, DDR200 (РС1600) и SDRAM PC100 остается прежней и равна 100 МГц. Из этого следует, что и латентность у вышеперечисленных типов памяти также одинакова. На практике это нисколько не снижает прирост быстродействия DDR II по сравнению с предшественниками в потоковых приложениях. Здесь ее преимущество может оказаться весьма ощутимым и, пожалуй, способно затмить даже RDRAM - наиболее приспособленного для потоковых приложений типа памяти. Поэтому, когда на рынке появятся первые модули DDR II, их задержки (CAS Latency Time, RAS-to-CAS Delay, RAS Recharge Time) составят 4-4-4. Но ждать низкой эффективности работы таких модулей не стоит, поскольку набор задержек 4-4-4 для DDR II будет приблизительно соответствовать формуле 2-2-2 для DDR SDRAM, а последний показатель в настоящее время характерен для наиболее производительных "оверклокерских" модулей памяти DDR.
Многие специалисты ожидают от DDR II более рационального потребления энергии.
Его уровень уменьшится со снижением потребляемого напряжения - с 2,5 до 1,8 В по сравнению с DDR SDRAM первого поколения. Если учесть, что выделяемое полупроводниками тепло при протекании электрического тока находится в квадратичной зависимости от приложенного напряжения, то первыми кандидатами на использование DDR II SDRAM после видеоадаптеров представляются мобильные системы. За счет использования микросхемных корпусов BGA, будет достигнута большая компактность модулей, а также в некоторой степени решена проблема воздействия на проводящие линии паразитной индуктивности проводников, что позволит производителям размещать функциональные элементы мобильных систем более компактно. Другое серьезное нововведение DDR II касается усовершенствования логики контроллера. В принципе, его можно рассматривать как следствие высоких задержек CAS Latency Time, RAS-to-CAS Delay и RAS Recharge Time, характерных для второго поколения DDR. Данную проблему, а также некоторые недостатки, свойственные протоколам работы SDR/DDR-памяти, должна решить технология "отложенного CAS" (Posted CAS) и механизм аддитивной латентности (Additive Latency). Чтобы лучше уяснить смысл нововведений протокола передачи данных в DDR II, необходимо вспомнить принцип работы протоколов, используемых SDR/DDR. Для синхронной памяти характерен следующий алгоритм работы: после получения запроса на ту или иную строку информации, размещенной в микросхеме памяти, интегрированный в чипсет контроллер подает запрос на активацию необходимого банка данных (Activate) и дожидается истечения задержки RAS-to-CAS Delay. По ее истечении происходит первый этап чтения, активируемый командой Read, после которого контроллер вновь выжидает CAS Latency Time. В это время информация переписывается в буфер памяти, и уже оттуда, запрошенная в начале транзакции строка данных попадает в контроллер чипсета. Описанная последовательность операций чтения может быть проведена еще раз лишь по истечении задержки Row-to-Row Delay. Слабость старого протокола открывается при подаче трех последовательно идущих запросов активации разных банков, когда первый сигнал чтения "перекрывается" третьим сигналом активации и должен создать конфликт в управляющих линиях.
Чтобы его избежать, чипсет с поддержкой первого поколения DDR "откладывает" выполнение третьего сигнала активации банка памяти, из-за чего пространство канала памяти используется неэффективно, ведь при работе нескольких приложений, активно применяющих ресурсы оперативной памяти, в трафике канала наблюдается слишком много "пустых" тактов. Особенно малонагруженным канал SDR/DDR-памяти оказывается при функционировании в серверах. Здесь длительные задержки просто губительны. Схема отложенного CAS подразумевает подачу сигналов запросов на активацию необходимого банка данных и начала чтения в буфер памяти (Read) без задержки CAS Latency Time. И хотя на практике без задержки обойтись нельзя в принципе (ведь активация банка не может произойти мгновенно), благодаря логике аддитивной латентности достигается увеличение эффективности использования физического пространства канала. Логика аддитивного времени выжидания (кстати, встроенная в чипы памяти) выслеживает все сигналы активизации банков и автоматически посылает сигнал чтения после их обнаружения. В результате, сразу после задержки CAS, память способна выдавать данные в чипсет, вне зависимости от числа активационных сигналов. Такое ухищрение, конечно, весьма эффективно для серверов и рабочих станций, однако на обычных ПК сильного прироста быстродействия все-таки не даст, ведь привносимое расширение пропускной способности будет несущественным. Весьма странным видится тот факт, что разработчики не внедрили в протокол режим динамического чередования банков памяти при чтении и записи, ведь такая организация протокола улучшила бы почву для действия механизмов логики Additive Latency, активизирующегося лишь при чтении из нескольких банков. Реализация схемы аддитивной латентности кажется недоработанной и по ряду других причин. Так, если в протоколах SDR/DDR-памяти запись в любых ситуациях осуществляется всего лишь за один такт, то в случае с DDR II она всегда происходит за число тактов на один меньше, чем при чтении, то есть динамически варьируется.
В итоге минимальное время записи информации в ячейку памяти может произойти не менее чем за три такта. Важно отметить, за счет того, что процессорное время тратится только на запись в буферы памяти, увеличение числа тактов записи не повлияет на скорость работы системы в целом, усложнив только работу логики контроллера. Если приложения сами смогут изменять величину Additive Latency соответственно своим нуждам, ее использование и в самом деле будет эффективным, однако ручная установка ее величины, практикуемая сейчас, может оказаться для некоторых приложений преградой к достижению оптимального уровня быстродействия. Предлагаемые в настоящее время производителями чипы DDR II способны изменять Additive Latency только с шагом 1 - от 0 до 4. Изложенные выше нововведения DDR II были бы малоэффективными и приводили, по меньшей мере, к повреждению целостности передачи данных, если бы не схемы поддержания качества сигналов. Известно, что на высоких частотах на любой сигнал начинает действовать суперпозиция внешних и внутренних электрических сил, способная в ходе передачи сигнала существенно повлиять на его форму, затруднив, таким образом, конечную дефиницию данных. Кроме того, передаваемые по шине канала памяти сигналы могут интерферировать. Во избежание проявления шумов в современных типах памяти применяется метод пассивной и активной терминации сигналов. Смысл последней заключается в установке заземляющих сопротивлений (пассивная терминация) на концах шины либо в подаче на ее выводы определенного сглаживающего напряжения (активная терминация), уровень которого может изменяться, в зависимости от амплитуды шумов. И тот, и другой способ стабилизирует сигнальную картину шины. Нововведением DDR второго поколения стало размещение стабилизирующих надстроек в кристалле чипа памяти, тогда как ранее они устанавливались или на материнских платах, или на самих модулях памяти. На практике это не только повысит стабильность передачи сигналов по шине канала памяти, но и удешевит материнские платы.Поэтому в будущем пользователь должен уделять особое внимание качеству приобретаемых модулей памяти, ведь применение некачественных образцов способно самым пагубным образом сказаться на стабильности системы в целом. Так как на высоких частотах на качество передачи сигналов может повлиять разная длина проводников шины, канал DDR II имеет двунаправленное стробирование сигнальных данных, взамен однонаправленного у DDR первого поколения. Этим достигается более точная дифференциация несущих информацию импульсов, ведь их идентификация теперь происходит по передней и задней кромкам сигнала. Также в контроллере DDR II реализована система автокалибровки сигналов, гарантирующая исключение разночтений при использовании модулей от разных производителей. Кроме того, данная система может оказаться востребованной, если у сигналов проявится скос контура или изменение амплитуды из-за скачков напряжения.
На перекрестке дорог
Экспресс-Электроника, #3/2004
Выход новых массовых чипсетов Intel Grantsdale с поддержкой DDR II вновь заставил думать о перспективности этого типа оперативной памяти. Но, как показывает статистика, настольные и мобильные ПК формируют лишь 8% спроса на рынке памяти, а потому судьба технологии Rambus не столь однозначна, как казалось когда-то.
Уже не раз говорилось, что перспективность той или иной технологии во многом определяют рыночные аспекты ее применения. И оспаривать этот факт бессмысленно, ведь вся история развития высоких технологий тому яркое подтверждение. А значит, противостояние стандартов памяти DDR II и RDRAM мы будем рассматривать как с точки зрения законов маркетинга, так и с точки зрения эффективности технологий. И если рыночная конъюнктура может быть понятна даже человеку, непосвященному в перипетии взаимосвязей разработчиков памяти и ее производителей, то детального рассказа о технологии функционирования конкурирующих стандартов не избежать.
RDRAM - путь взлетов и падений
Главный секрет привлекательных технических характеристик памяти RDRAM - оригинальное устройство шин передачи данных и адресации. В отличие от SDRAM, DDR и DDR II обмен данными в RDRAM происходит по шине, а не по параллельному интерфейсу. Для этого в RDRAM специально выделяется два отдельных набора контактных дорожек, по 16 штук каждый, образующих полосу шириной 2 байта. А уже на эту, общую для всего модуля шину и "присаживаются" все его чипы. Как это работает? Достаточно прозаично, если учесть, что похожая схема применена и для передачи данных в технологии Ethernet. Разница состоит лишь в том, что в сетевом протоколе применяется дифференциальное кодирование сигналов для каждого проводника, тогда как Rambus при разработке своей высокоскоростной шины отталкивалась от идеи минимизации количества выводов микросхем. Ведь это имеет особенно большое значение для многоканальных конфигураций, поскольку уменьшает число проводников, упрощает разводку сигнальных трасс и удешевляет системные платы. Как следствие, вместо нескольких отдельных парных Ethernet-проводов, RDRAM использует всего один-единственный провод-эталон нулевого уровня сигнала, служащий общим для всего набора сигнальных проводников шины. Безусловно, такой подход несет очевидные сложности по организации четкой детерминации сигнала, на который из-за общих наводок сигнальных проводников могут быть оказаны взаимные помехи, но если учесть "миниатюрность" шины RDRAM, то использования полноценной дифференциальной схемы можно все-таки избежать. Что, вообще-то, и наблюдается в чипах данного вида памяти, где всего 30 физических каналов отвечают за прием и передачу данных, а также управляющей информации, а оставшиеся пять - за электропитание микросхем и подачу инициализирующих команд.
Впрочем, высокая скорость передачи данных, а также недоступная для конкурентов частота работы интерфейса RDRAM (до 1200 МГц) является не только следствием использования техники передачи сигналов по двум фронтам тактовых импульсов, но и технологии Quad Rambus Signalizing Levels.
Последняя позволяет кодировать данные в канале памяти RDRAM четырьмя уровнями напряжения (в DDR II их всего два). В итоге пропускная способность одного 16-битного "квадро-канала" Rambus, функционирующего на частоте 1066 МГц, выливается в недостижимые для конкурентов 4,2 Гбайт/с. Однако, как и в случае с DDR II, эти цифры имеют мало общего с показателями реальной производительности. Стоит понимать, что пиковые показатели работы любой памяти зависят от множества факторов, и в частности от ряда характеристик, присущих как микросхемам памяти, так и их контроллеру, например латентности, скорости считывания и записи, и других. Как и технология DDR II, RDRAM несет в себе ряд энергосберегающих функций. И если в DDR II они являются следствием новой "упаковки" микросхем и снижения уровня рабочего напряжения, то в RDRAM применено более интересное инженерное решение. Речь идет о по-настоящему новом слове в области организации работы памяти - создании четырех режимов энергопотребления - активного (Active), ожидания (Standby), экономного (Nap) и сна (PowerDown). В первом режиме RDRAM может мгновенно обработать запрос на передачу данных. Естественно, этот режим характеризуется самым высоким энергопотреблением. Режим Standby - обычное состояние ожидания запроса. В нем находятся все устройства, не принимающие участия в передаче. В отличие от обычных систем памяти на основе DRAM, где все устройства, входящие в банк, потребляют энергию во время операций записи-чтения, в памяти Rambus это происходит только с одним устройством - остальные переходят в режим ожидания. Режимы Nap и PowerDown еще более экономны. Между собой они различаются уровнем потребления и скоростью перехода в активное состояние. Но вернемся к принципу организации работы RDRAM. Как уже отмечалось, для передачи управляющих команд данный тип памяти имеет "выделенные" линии - ROW и COL. По ним передаются пакеты данных, состоящие из двух полей. В первом поле указывается тип операции, а во втором размещается либо битная маска, которая используется для расширения операции записи превышающих стандартный объем пакета данных, либо код расширения (уточнения) характера операции.
Для того чтобы разгрузить шину, в нее введено искусственное занижение скорости работы Rambus-микросхем - поля пакета отсылаются с четырехтактовым интервалом. Операция чтения также имеет свои особенности. Например, во время инициализации шины, производится нумерация чипов от контроллера и далее. После этой процедуры каждому чипу на основе полученного номера выдается значение задержки отправки данных в ответ на запрос о чтении некоторого целого числа тактов по принципу - чем ближе к контроллеру чип, тем большую задержку он для себя устанавливает. Как следствие, временные параметры операций записи выставляются таким образом, чтобы они совпадали с задержками, выставленными для чтения. Итог подобного "мошенничества" прост - контроллеру Rambus нет необходимости выдерживать искусственные задержки, присущие DDR-памяти, у него всегда наготове ячейки памяти. Что касается будущего данной технологии, по мнению компании Rambus, в сфере ПК оно связано с набором расширений RDRAM под название Yellowstone. Эта более быстрая сигнальная технология подразумевает смену сигнальной архитектуры Quad Rambus Signaling Level на еще более эффективное решение. Речь идет о новой технологии ввода/вывода, которая была названа ячейкой RaSer (Rambus Serializer/Deserializer). Под "ячейкой" в данном случае понимается любой элемент набора микросхем. Технологию RaSer можно использовать для организации связи между отдельными микросхемами или платами. Она способна заметно увеличить скорость передачи данных через маршрутизаторы глобальных сетей, а также через интерфейсы Fibre Channel, Gigabit Ethernet и InfiniBand. В настоящее время существуют одно-, двух- и четырехканальные конфигурации ячеек. Четырехканальная конфигурация обеспечивает пересылку информации со скоростью до 12,5 Гбит/с в каждом направлении. Интереснейшая особенность Yellowstone - технология FlexPhase, назначение которой в автоподстройке фаз сигналов данных и адреса для упрощения разработки межчиповых соединений. FlexPhase выравнивает данные по частоте, упрощая расчеты длин линий шин и проектирование печатных плат.Обещают, что ее действие не будет вносить задержек в работу интерфейса. Хочется верить, что интеграция этой технологии в микросхемы памяти не приведет к их значительному удорожанию. Уже существуют тестовые образцы чипов по техпроцессу 0,13 мк, реализующие технологию FlexPhase. В итоге, Yellowstone сможет предложить пропускную способность (с учетом двунаправленной шины), превосходящую DDRII в четыре раза.
Авторегенерация
осуществляется на том банке памяти, к которому на текущий момент обращений нет.
CAS#
(Column Address Strobe) ().
При доступе к шинам строк активизируется числовая шина, и все ячейки в данной строке считываются. На разрядные шины поступают соответствующие потенциалы от конденсаторов. На активизацию шин столбцов, подключение разрядных шин к буферу данных и извлечение из ячейки памяти данных также требуется два-три такта синхронизации. Еще один такт уходит на доставку данных в буфер данных DRAM. По такту затрачивается на доставку данных в контроллер ОЗУ и далее — в процессор.
Таким образом, за один цикл обращения к памяти система генерирует, в общей сложности 9–11 тактов синхронизации. При считывании данных следует учесть еще два такта, расходуемых на восстановление заряда ячеек.
Что может быть лучше «простой» SDRAM
Новые технологии синхронной памяти, многобитные модули ОЗУ, а также оптимизированные циклы группового обмена данными и пакетная передача сигналов управления действительно позволили повысить производительность системы. Хотя на доступ к ОЗУ расходуется и меньше тактов синхронизации, процент тактов ожидания процессора по-прежнему велик (рис. 9).

Преодолеть ограничения, присущие архитектуре традиционной DRAM, стало возможно благодаря технологии DR DRAM (Direct Rambus DRAM). Идейными вдохновителями движения Rambus стали корпорации Intel Corporation и Rambus Inc., заключившие в 1996 г. договор о сотрудничестве. Усилия альянса по созданию быстродействующего ОЗУ поддерживаются ведущими фирмами отрасли, такими как Micron, Samsung, Toshiba и др. (рис. 10).

DDR SDRAM
(Double Data Rate SDRAM) — тип памяти, который «роднит» с SDR SDRAM (Single Data Rate SDRAM) общий тракт обработки адресов и сигналов управления, одинако вая конструкция банков памяти и общие методы регенерации (см. ).
Основные отличия этих технологий (см. табл. 2) — в организации интерфейса данных и системе синхронизации. DDR работает на удвоенной частоте.

Динамическая память набирает обороты
Олег Степаненко, Компьютеры + Программы
ЗУ - один из источников машинного "интелекта" - вынуждено постоянно следовать в "кильватерной струе" быстродействия микропроцессора. Баланс производительности между этими центральными элементами системы в последнее время несколько выровнялся и не вызывает уже недоуменного вопроса: а точно ли мы подсчитали такты ожидания?
История динамической памяти с произвольным доступом (DRAM, Dynamic Random Access Memory) - один из примеров отличной проработки удачной идеи, однажды осенившей исследователей.
DR
— разновидность быстрой динамической памяти с произвольным доступом. Основа архитектуры Rambus — банки памяти, «пронизанные» скоростным каналом. Канал представляет собой электрическую шину, подключающую элементы памяти к контроллеру и разъемам (рис. 11). Канал входит в модуль на одном его конце, проходит через все чипы и выходит на другом конце модуля.
Шина данных синхронизируется отвнешнего источника 400 МГц, как и DDR SDRAM, фронтом и срезом, благодаря чему тактовая частота синхронизации памяти — 800 МГц.
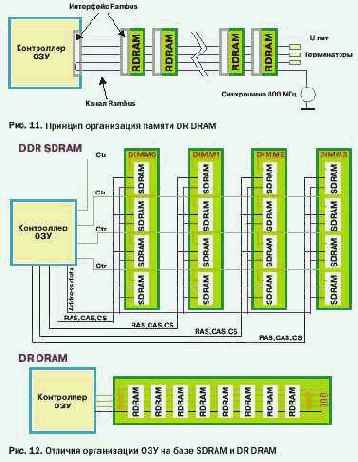
Структурные отличия модулей SDRAM и DR DRAM иллюстрирует рисунок 12.
Значительные усовершенствования в DR DRAM коснулись структуры и организации банков памяти. Если модуль DIMM SDRAM содержит всего лишь 4 банка, то 128 Мбит чип DR DRAM располагает 32 банками. Современные RIMM (Rambus In line Memory Module) могут содержать до 128 банков памяти.
Благодаря конвейеру, поток данных малыми порциями распределяется между банками таким образом, что потери времени при обращении к памяти минимальны. Распределение данных зависит от скорости заполнения каждого банка. Большое число банков позволяет эффективно использовать синхронную внутреннюю высокоскоростную магистраль данных.
Два канала данных (каждый шириной по байту) позволяют получить пиковую пропускную способность выходной шины данных до 3, 2 Гб/с. В дальнейшем для работы DR DRAM с процессором Pentium 4 планируется использовать ускоренную системную шину (533 МГц), разрабатываемую Intel. В планах альянса: к 2002 г. адаптировать DR DRAM для работы в соответствии со спецификацией PC1066, а к 2005 г. — PC1200. Таким образом, в 2005 г. планируется на базе 0,12 мкм технологии выпустить 32/64 разрядные модули ОЗУ с пропускной способностью памяти DR DRAM 9, 6 Гб/с.
FSB
(Front Side Bus) — тактируется системными синхроимпульсами. При отсутствии данных в кэш, доступ к ОЗУ можно представить следующим образом.
За время первого и второго тактов синхронизации с шины FSB в контроллер ОЗУ направляются управляющие и адресные сигналы (# у сигнала свидетельствует о том, что его активный уровень — низкий). Сигналы анализируются и управляют логикой ОЗУ.
Два-три (в зависимости от качества DRAM) синхроимпульса расходуется на запуск схемы дешифрации и выбор соответствующей строки.
Каждый из элементов адресной группы стробируется импульсами сигналов управления
Ячейка – базовый элемент памяти
Парадоксально, но динамическая память способна запоминать нолики и единички благодаря паразитной емкости, с которой электронщики ведут долголетнюю борьбу. Это — квинтэссенция конструкции, смонтированной на базе структуры комплиментарной технологии металл-оксид-полупроводник (CMOS, Complimentary Metal Oxide Semiconductor ).
По CMOS технологии, благодаря ее несомненным техническим достоинствам, строятся современные чипы быстродействующих электронных элементов с высокой плотностью упаковки.
Как DRAM избавлялась от «вредных привычек»
Архитектурные и технологические решения позволяют минимизировать в DRAM временные задержки (латентность).
Когда процессор "гуляет"
Систему притормаживают не только задержки в «недрах» памяти. Любое обращение к ОЗУ сопровождается передачей в контроллер памяти большой группы сигналов, осложняющих схемотехнику. Громоздкость сигнального аппарата повышает латентность подготовительного периода цикла обмена данными. О чем идет речь?
В DRAM каждую ячейку можно отыскать по ее адресным координатам, оформленным в строки и столбцы (рис. 2 ).
Все ячейки выводятся на общую числовую шину. Выбор соответствующего адреса строки и столбца позволяет определить место ячейки. Содержимое нескольких ячеек, объединенных на выходе, образует информационную группу — байт, или слово, и следует на шину данных памяти. Разрядность внешней шины данных памяти позволяет повысить ее пропускную способность. Вместе с тем рост быстродействия памяти не возымеет никакого эффекта, если она не способна работать с малыми временными задержками.

Адрес памяти содержит сведения для выбора: байта, банка, строки и столбца. Он поступает в один из портов контроллера ОЗУ, трансформируется в два адреса — строки и столбца, которые по шине MA попадают в DRAM (рис. 3) с некоторым промежутком времени (ΔT1 на рис. 4).

Контроллер памяти оснащен портом для обмена данными с процессором и еще одним портом — для обмена с устройствами ввода вывода на системной шине. В современных чипсетах первый порт называется «северным», а другой «южным». С таким же успехом порт AGP может быть назван «западным»… Поскольку «соискателей» для обмена много, на входе подсистемы имеется арбитр. Этот «строгий привратник» подключает к памяти устройства в соответствии с приоритетами. На этот процесс также уходит время.
Шина между процессором и контроллером ОЗУ —
Микросхема DRAM
содержит множество элементарных ячеек, одна из которых изображена на рис. 1.
Транзистор в динамической ячейке работает как ключ, управляющий передачей заряда. При записи в конденсатор бита информации ключ открывается, заряжая конденсатор до определенной величины.
На что способноОЗУ вашего ПК?
Быстродействие ОЗУ зависит не только от архитектурных и конструктивных особенностей модулей памяти, но также и от режимов обмена, показателей центрального процессора, чипсета и прочих системных устройств, влияющих на синхронизм обмена и латентность.
Что следует учесть для определения быстродействия SDRAM в следующих режимах: кэш попадание; кэш промах с выборкой из текущей строки; кэш промах с выборкой из другой строки.
В третьем, наиболее жестком, режиме требуется восстановление заряда ячеек предыдущей строки и выбор новой, текущей. На этот процесс (precharge time) расходуется два дополнительных такта.
В рассмотрены некоторые задержки, характерные для отмеченных режимов и определено быстродействие памяти на шине PC133.
Быстродействие ОЗУ повышается, если чипсет работает с ОЗУ и процессором синхронно и согласованно (см. ). Синхронизм между шинами памяти и процессора обеспечивает оптимальный, скоростной режим работы системы. Если частоты на шинах отличаются, данные, пересылаемые через чипсет, буферизируются. Для согласования скоростей на шинах требуются дополнительные такты ожидания.
Таким образом, недостаточно оценивать быстродействие ОЗУ, руководствуясь только конструктивными и технологическими достоинствами микросхем и модулей памяти. Немалое влияние на показатели производительности оказывают характеристики системных устройств — центрального процессора и компонентов подсистемы памяти. Скорей всего, оптимальным решением может стать интеграция в одном модуле компонентов, изображенных на .

ОЗУ подвержено «склерозу»
После отключения питания ОЗУ, оно напрочь забывает о том, какой оперативной работой занималось до того, как вы нажали на кнопку Power. Более того, если бы не специально предпринимаемые меры, ОЗУ «умудрилось» бы позабыть, что хранило в своих ячейках с десяток миллисекунд назад. Это связано с естественным процессом утечки тока с емкости.
В отличие от Statics RAM, динамическая память энергозависима и требует периодического восполнения энергии в паразитных емкостях, что реализуется стандартной процедурой регенерации. Эта аппаратная процедура инициируется интервальным таймером каждые 15,6 мкс () и выполняется через канал ПДП. Для регенерации используются только стробы RAS#, а стробы CAS# в процессе не участвуют.
На протяжении этого времени, называемого шагом регенерации, в DRAM перезаписывается целая строка ячеек. Так, на протяжении 8–64 мс обновляются все строки памяти.
Для перезаписи ячеек ОЗУ достаточно перебирать строку за строкой и выполнять «фиктивную» (без вывода данных на магистраль данных памяти) команду чтения. В этом случае каждая ячейка строки перезапишется через схему предзаряда, а данные не попадут в буферы выхода данных. Шина данных — в высокоимпедансном состоянии. На модификацию ячейки при считывании расходуется два такта синхронизации.
Очевидно, что процедура регенерации памяти (в классическом варианте) «тормозит» работу системы, поскольку в это время обмен данными с ОЗУ невозможен. Регенерация, основанная на обычном переборе строк (независимо в какой последовательности) в современных типах DRAM не применяется. Существует несколько экономичных вариантов этой процедуры — расширенный, пакетный, распределенный и пр.
Регенерация с циклом CBR (CAS Before RAS) более практична. Начало процесса инициируется контроллером ОЗУ и индицируется синхростробами. Срез строба RAS# помещается в промежуток времени низкого уровня CAS#. Внутренний счетчик перебирает адреса строк для регенерации. Для выполнения регенерации типа CBR также используется прием «фиктивного» чтения.
Наиболее экономична скрытая регенерация. Каждый рабочий цикл чтения или записи сопровождается удержанием строба CAS# в низкоуровневом состоянии. На протяжении этого периода времени, уровень строба RAS# нарастает и падает — и микро схема, в соответствии с показанием внутреннего счетчика, выполняет цикл регенерации. Регенерация протекает не при фиктивном, а при реальном считывании данных из буфера, что не вызывает потерь времени.
Из новых технологий регенерации выделим PASR (Partial Array Self Refresh), применяемую Samsung Electronics в чипах памяти SDRAM с низким уровнем энергопотребления. Регенерация ячеек выполняется только в период ожидания в тех банках памяти, в которых имеются данные. Параллельно с этой технологией реализуется и метод TCSR (Temperature Compensated Self Refresh), предназначенный для регулировки скорости регенерации в зависимости от рабочей температуры.

Память DRAM FPM
и ее модификации — EDO (Extended Data Out) и BEDO (Burst EDO) применялись для группового обмена с ОЗУ. В EDO совмещены по времени операция передачи в ОЗУ адреса и выборка текущих данных. Благодаря этому и удается выиграть пару тактов.

В таблице 1 рассмотрены характеристики некоторых типов памятиDRAM.
Саморегенерация
производится постоянно в любой области памяти за исключениям тех блоков, к которым обращается система с текущим запросом.
Архитектура синхронной памяти имеет модификации.
Считывание информации
— процесс длительный, включающий подготовительные операции. Вначале специальная схема предзаряда сообщает потенциал (опорное напряжение) обеим разрядным шинам. Схема также модифицирует ячейку, восстанавливая информационную емкость после чтения (откуда и название режима работы — чтение с модификацией)).
Далее для доступа к микросхеме памяти из контроллера ОЗУ поступают сигналы управления, которые переводят числовую шину в активное состояние. При этом на числовой шине ячейки также повышается потенциал, транзистор открывается и замыкает цепь: корпус — числовая шина 1.
Если емкость заряжена, она разряжается на числовую шину, повышая ее потенциал. Между числовыми шинами 1 и 2 возникает напряжение. Циркулирующий при этом ток создает на выходной шине заряд (единица). Если емкость не была заряжена, то на выходе формируется ток противоположного направления и с шины данных снимается ноль.
Процесс записи обратен считыванию.
Временных характеристик динамической памяти очень много, но важнейших — три: время предзаряда памяти — представляет собой задержку, связанную с предварительным зарядом разрядных шин опорным напряжением; время доступа к памяти — активизация числовой шины, в результате чего на выходную шину данных памяти выкладывается информация; время цикла — состоит из задержек времени предзаряда и доступа.
Время задержки вывода данных DRAM измеряется величинами от десятков до сотен наносекунд.
Сильные стороны синхронизма
Наиболее радикальные изменения коснулись DRAM с внедрением технологии синхронной динамической памяти (SDRAM, Synchronous DRAM). Для того чтобы синхронизировать память извне, в чип была вмонтирована логика управления. Таким образом, узлы памяти перебрали ряд функций контроллера ОЗУ. В память поступают команды, которые обрабатываются непосредственно в чипе (). Синхронизм позволяет микросхеме SDRAM выполнять операции независимо от задержек внешних сигналов управления. Внедрение в чип механизма управления и упрощение схемотехники сократили накладные расходы времени доступа к ОЗУ.
Следовательно, чип SDRAM представляет некое подобие микроконтроллера со встроенными элементами динамической памяти. Микросхема содержит скоростную синхронную шину данных. Для доступа к данным используется трехступенная конвейерная архитектура с интерливом. SDRAM содержит защелки и счетчик адреса столбцов (). На открытой строке счетчик последовательно перебирает адреса столбцов, и за каждый такт из защелок данных шлюза ввода вывода в выходной буфер перемещается по восемь байтов данных.
Таким образом, за четыре обращения к памяти считывается полная строка (32 байта). Первое обращение к восьми байтам (при промахе кэш) занимает 9–11 тактов. На каждое последующее расходуется по такту.
Команды загружаются в память SDRAM через программируемый регистр режима. Регистр позволяет запрограммировать память для выбора режима регенерации, автоматической выборки расположенных смежно ячеек памяти в пределах банка, а также применение интерлива. Может быть запрограммирована длина пакета и изменено время задержки стробов CAS#. Настройка этой задержки сказывается на производительности системы.
Конвейерная обработка пакетов данных позволяет исключить из списка временных потерь весьма существенные позиции. Внутреннее выполнение команд снимает с системных шин часть нагрузки и ускоряет процесс доступа к данным.
Выполнение команд обеспечивает оперативную регенерацию в наиболее благоприятные для памяти моменты времени. В SRAM применяется авторегенерация и саморегенерация.
SL DRAM
(Synchronous Link DRAM) — это также синхронная память. Как и DDR, она синхронизирует данные фронтом и срезом тактового импульса. Управляющая информация, как и данные, передается в память пакета ми, что уменьшает латентность. Память SL содержит расширенный файл программируемых регистров и справляется с большим числом команд.
Страничная память в интерлив
Не ищите в ОЗУ страницу. Это — логическая категория, существующая для удобства обращения. Память разбивается на четное количество банков, состоящих из страниц малого объема.
При каждом обращении контроллерпамяти генерирует адресные элементы для доступа к строкам и к столбцам. Между этими операциями существует временной «зазор» (ΔТ1), который, накапливаясь, приводит к высокой латентности. Доступ к памяти в режиме быстрого страничного обмена (FPM, Fast Page Mode) позволяет минимизировать эти потери.
Временной выигрыш при доступе к ОЗУ в режиме FPM состоит в том, что задержки (ΔТ1) возникают лишь при первом доступе к ячейкам страницы. Потери времени на первое обращение к ОЗУ, вне зависимости оттипа DRAM, — «ахиллесова пята» динамической памяти.
Все последующие обращения к столбцам страницы выполняются на уже выбранном адресе строки (открытой строке). Таким образом, адрес строки активен на протяжении всех циклов доступа к строке памяти, а адреса столбцов стробируются импульсами CAS# каждый раз, когда в этом есть необходимость ().
Интерлив, или чередование банков, — режим работы, используется всеми модулями динамической памяти. Как известно, каждое последующее обращение к DRAM возможно лишь по завершению переходных процессов в ячейках.
В памяти с интерливом каждая последующая строка выбирается в новом банке, что позволяет ячейкам строки из предыдущего банка восстановить свои кондиции. Увеличение количества последовательно выбираемых банков памяти способствует снижению временных потерь, связанных с перезарядкой емкостей.
